ASyncHTTPClient Monitoring
MASyncHTTPClient monitoring with Atatus Java Agent empowers you to gain deep visibility into asynchronous HTTP requests, uncover performance bottlenecks, and optimize error handling. Ensure faster, more reliable API integrations with real-time insights into every async call.
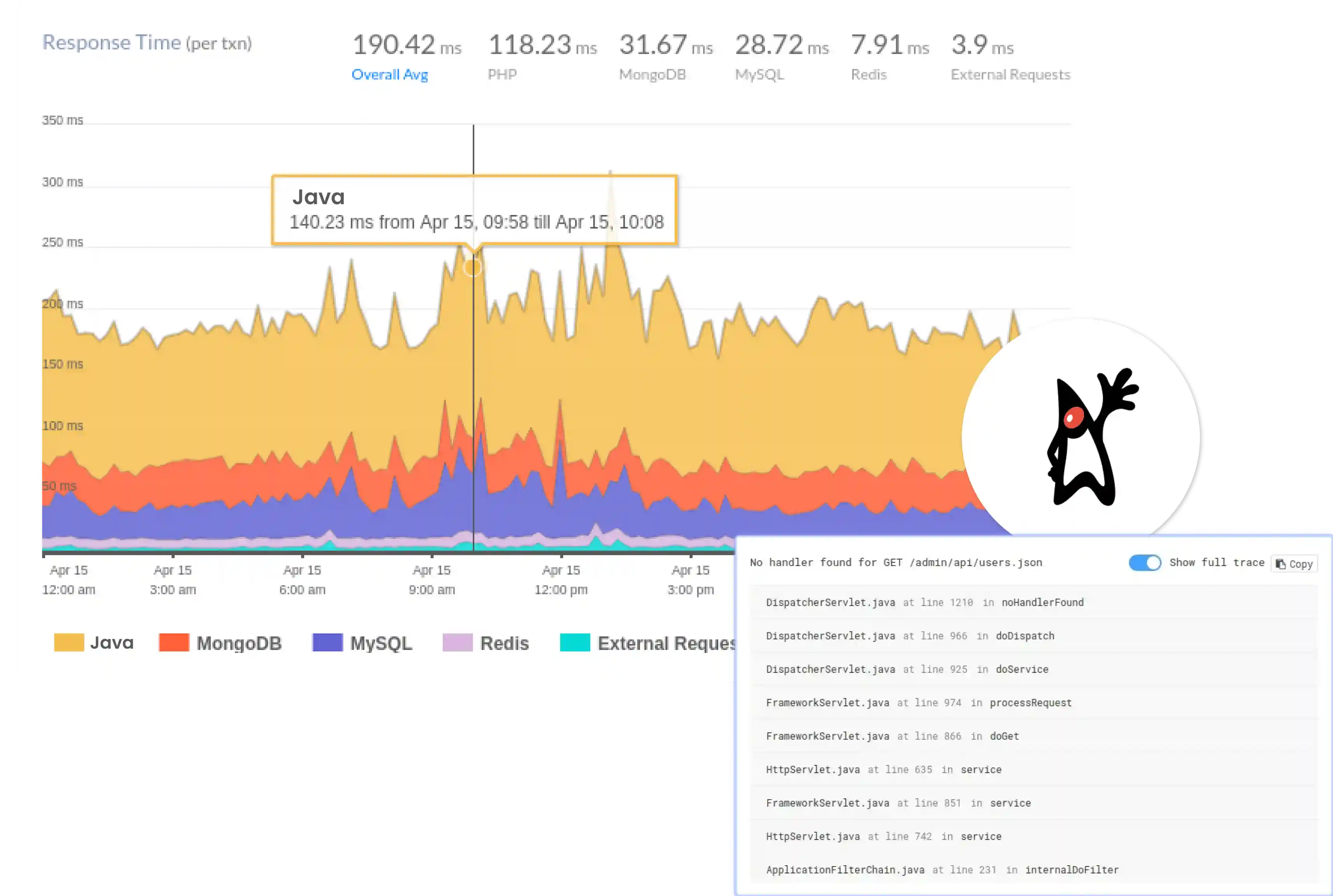
Where AsyncHttpClient production clarity breaks
Request Lifecycle Ambiguity
Asynchronous request execution spans multiple callbacks and states, making it difficult to confirm how requests actually progressed under live traffic.
Fragmented Async Context
Failures surface without complete callback or execution state, forcing engineers to reconstruct async flow after the incident.
Slow Failure Attribution
Determining whether issues originate locally or in downstream systems takes longer as failures propagate asynchronously.
Hidden Remote Latency
Downstream services introduce variable delays that remain invisible until they begin impacting upstream systems.
Retry Behavior Uncertainty
Automatic retries and fallback paths alter execution patterns in ways teams cannot easily observe in production.
Noisy Timeout Signals
Timeouts and connection errors trigger alerts without sufficient context to distinguish systemic issues from isolated failures.
Concurrency Saturation Effects
Increasing parallelism stresses event loops and connection pools, changing runtime behavior in subtle, hard-to-observe ways.
Declining Signal Confidence
Repeated blind investigations reduce trust in production signals, slowing decision-making during critical incidents.
Complete Performance Visibility for
AsyncHttpClient
Real-time observability for AsyncHttpClient that helps teams analyze request latency, monitor throughput, and maintain reliable asynchronous communication at scale.
Response Time Metrics
Track how long each outbound request takes to complete. Quickly identify slow responses impacting application performance.

Latency Distribution
Analyze response time percentiles to understand typical and worst-case latency behavior. Spot performance degradation early.

Throughput Trends
Monitor request volume and processing rate over time. Detect drops or spikes affecting service stability.

Timeout & Retry Counts with Concurrency Levels
Track timeout events, retry attempts, and concurrent requests together. Understand how network behavior impacts overall performance.


Why AsyncHttpClient teams standardize on Atatus
As outbound traffic becomes mission critical, understanding asynchronous execution behavior under real load is no longer optional. Teams standardize on Atatus to preserve execution clarity, align engineers around the same runtime reality, and maintain confidence as concurrency and dependency complexity grow.
Coherent Async Visibility
Engineers maintain a clear understanding of how asynchronous requests execute across callbacks and execution states.
Fast Team Alignment
Platform, SRE, and backend teams share the same understanding of outbound behavior without extended investigation handoffs.
Immediate Signal Confidence
Production signals are trusted early in investigations, enabling faster and more confident incident response.
Reduced Debug Complexity
Engineers spend less time stitching together async callbacks and more time validating root causes.
Predictable Incident Analysis
Incident response follows consistent reasoning patterns despite asynchronous execution complexity.
Shared Runtime Evidence
Teams reference the same execution context during outages and post-incident reviews.
Stable Under Concurrency
Production understanding remains intact as request volume and parallelism increase.
Lower On-Call Fatigue
Clear async execution insight shortens incident duration and reduces escalation loops.
Long-Term Operational Confidence
Teams continue scaling outbound integrations without fear of unseen async failure behavior.
Unified Observability for Every Engineering Team
Atatus adapts to how engineering teams work across development, operations, and reliability.
Developers
Trace requests, debug errors, and identify performance issues at the code level with clear context.
DevOps
Track deployments, monitor infrastructure impact, and understand how releases affect application stability.
Release Engineer
Measure service health, latency, and error rates to maintain reliability and reduce production risk.