Node.js Application Performance Monitoring
Monitor Node.js applications with real-time APM, distributed tracing, and memory leak detection. Track Express, NestJS, and Fastify performance. Reduce MTTR by 60% with intelligent alerts and database query optimization. Start free trial.
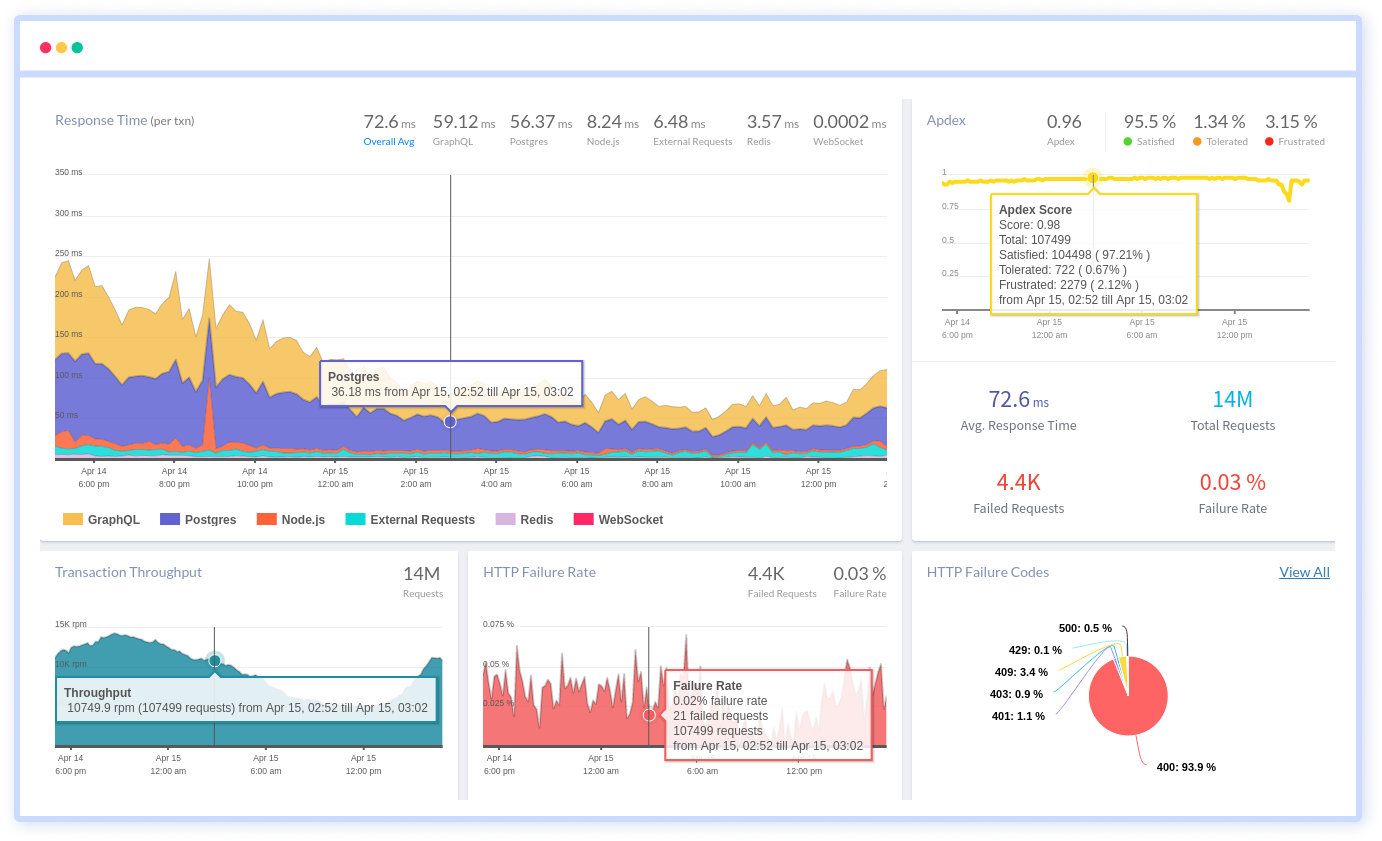
How disconnected signals slow Node.js teams?
Lost Execution Flow
In live systems, execution paths fragment quickly. Asynchronous work branches across multiple layers, breaking the original flow. When something goes wrong, engineers cannot reconstruct what actually happened end-to-end.
Contextless Errors
Failures surface as isolated signals with little surrounding state. By the time an error appears, the conditions that caused it are already gone, forcing engineers to reason backward with incomplete information.
Hidden Latency
Slowdowns rarely come from a single hotspot. Latency accumulates quietly across I/O waits, scheduling delays, and external dependencies, making performance issues hard to localize.
Scale Uncertainty
Higher throughput amplifies small inefficiencies. Behavior becomes inconsistent under sustained load, increasing variance without making root causes obvious.
Manual Debugging
Investigation relies heavily on intuition, logs, and past experience. Outcomes depend on who is available rather than on a shared understanding of system behavior.
Slow Analysis
Service recovery happens faster than explanation. Post-incident analysis drags on long after impact, often ending without clear or actionable conclusions.
Production Drift
Real-world usage introduces patterns never seen in testing. Systems behave differently under real concurrency and data, creating blind spots that only exist in live environments.
Eroding Confidence
Repeated unknowns reduce trust in the system. Teams hesitate to change code, not due to risk in the change itself, but due to uncertainty in runtime behavior.
Everything You Need to Monitor & Optimize
Node.js Applications
Real-time observability built for modern Node.js workloads to help teams catch issues faster, improve performance, and ship with confidence.
Trace-level Visibility Across Your Node.js Stack
Track every request across services, APIs, and databases in a single end-to-end trace. Get full visibility into async operations, execution flow, and performance behavior across your Node.js application.

Visualize Service Dependencies
Understand how Node.js services interact with databases, message queues, caches, and external APIs. Identify latency spikes, throughput changes, and failure patterns to eliminate bottlenecks proactively.

Monitor Critical Transactions
Track high-impact user journeys such as signups, payments, API workflows, and background jobs. Quickly spot slow endpoints, rising error rates, and performance regressions affecting user experience.

Track External Dependencies
Monitor third-party APIs, microservices, and integrations your Node.js apps depend on. Detect slowdowns and outages early to prevent cascading failures in production.


Why Teams Choose Atatus for Node.js Monitoring?
Teams choose Atatus for clear visibility into Nodejs performance without adding complexity to their stack.
Shared Clarity
Teams want a consistent view of how their Node.js systems behave in production. Atatus aligns engineers around observable reality rather than assumptions.
Faster Alignment
During incidents, teams need to agree quickly on what is happening. Atatus helps reduce debate and focus attention on what matters.
Natural Adoption
Engineering tools must fit existing mental models. Atatus resonates with how Node.js engineers reason about execution, state, and failure.
Production Insight
Teams prefer to debug directly from real behavior instead of recreating issues locally. Atatus supports reasoning from production conditions.
Technical Trust
Consistency builds confidence. Engineers rely on Atatus because it reflects what they see in real outcomes.
Clear Models
As systems grow more complex, maintaining clarity becomes harder. Atatus helps teams preserve simple mental models across expanding architectures.
Team Readiness
Engineers with different experience levels can reach the same conclusions without relying on undocumented knowledge or individual memory.
Faster Shipping
Understanding reduces hesitation. Teams move faster when decisions are grounded in clear system behavior.
Operational Stability
Atatus is chosen for long-term reliability. Teams spend less time firefighting and more time improving their systems.
Unified Observability for Every Engineering Team
Atatus adapts to how engineering teams work across development, operations, and reliability.
Developers
Trace requests, debug errors, and identify performance issues at the code level with clear context.
DevOps
Track deployments, monitor infrastructure impact, and understand how releases affect application stability.
Release Engineer
Measure service health, latency, and error rates to maintain reliability and reduce production risk.