Golang Logs Monitoring & Observability
Effortlessly track Golang logs, gaining instant insights into errors and refining logging for a more efficient and reliable application.
Monitor Golang application logs and runtime metrics in production systems
Centralize Go application logs
Collect logs written by Golang services using standard library logging and structured loggers such as zap or logrus across APIs and background processes.
Analyze HTTP and gRPC traffic
Inspect logs generated by net/http handlers and gRPC interceptors to understand request flow, response latency, and transport-level errors.
Observe goroutine behavior
Monitor runtime metrics related to goroutine counts and scheduling while correlating log events emitted during concurrent execution.
Track memory and garbage collection
Ingest Go runtime metrics for heap usage, allocation rates, and garbage collection pauses alongside application logs.
Correlate logs with request metrics
Link structured Go logs with request duration, status codes, and handler-level metrics to investigate performance regressions.
Monitor service startup and crashes
Capture startup logs, panic stack traces, and unexpected process exits to diagnose deployment and runtime failures.
Debug concurrency and blocking
Use logs and runtime signals together to identify goroutine leaks, blocking calls, and resource contention under load.
Support containerized Go services
Aggregate logs and metrics from Golang services running in containers or virtual machines for centralized operational visibility.
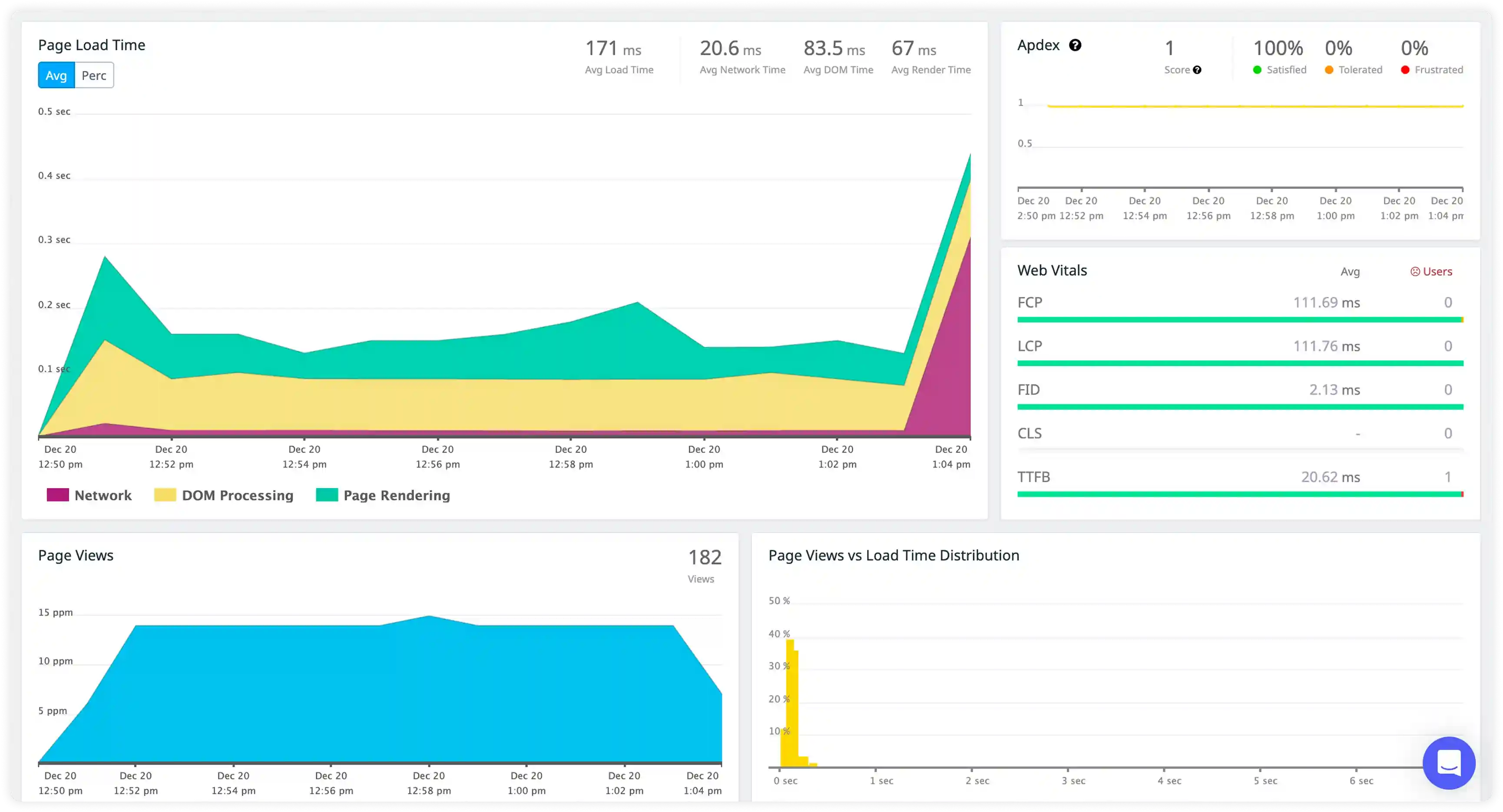
Goroutine and Execution Flow Visibility
- Track log generation across goroutines, service handlers, and background processes to understand concurrent execution behavior in Go applications.
- Correlate log entries with request context, service interactions, and execution paths across distributed workloads.
- Identify failures in concurrent task execution, service handling, and background processing affecting system reliability.
- Detect disruptions in request handling and goroutine scheduling impacting service responsiveness.
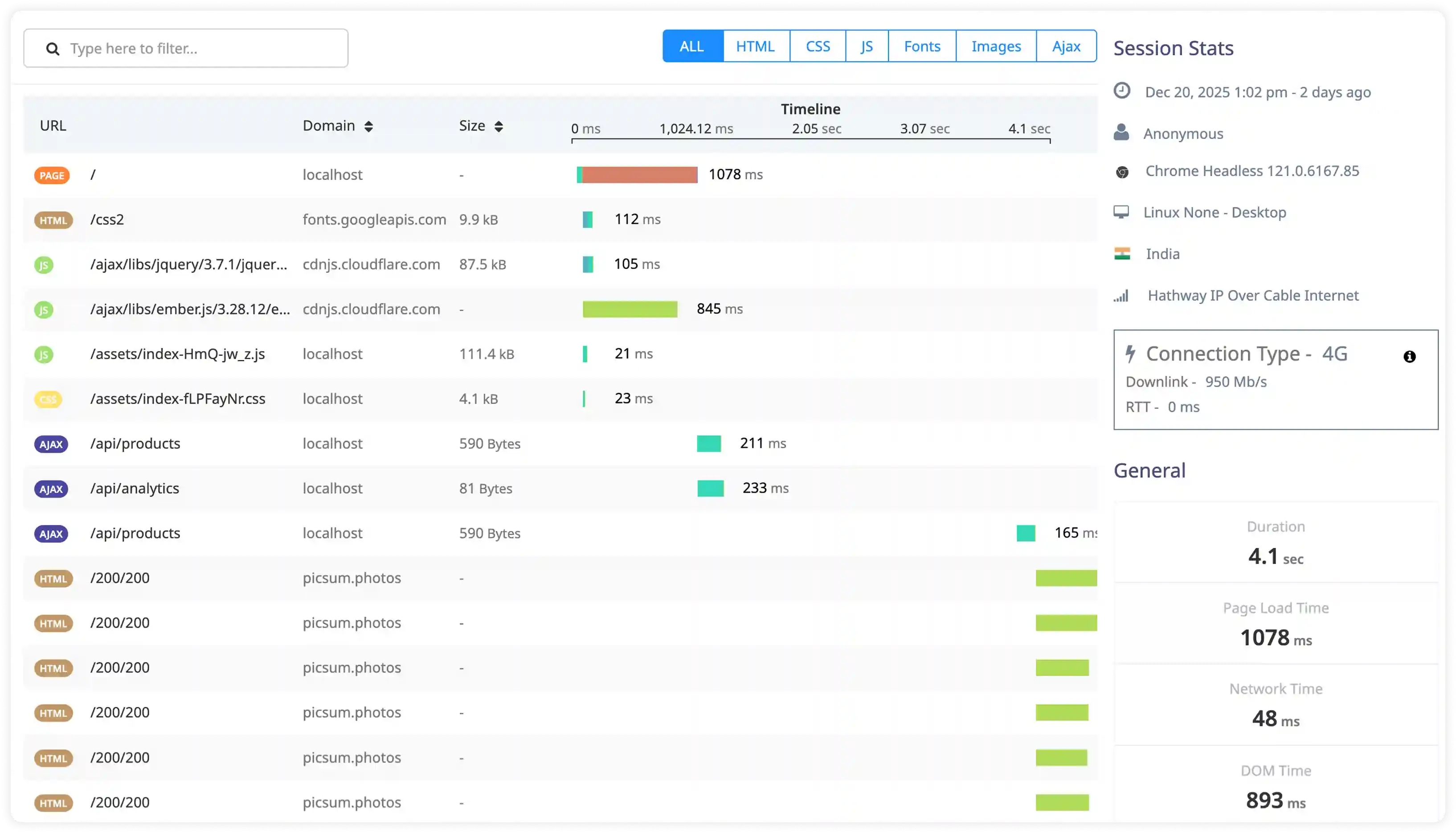
Runtime Errors and Panic Diagnostics
- Capture runtime errors, panic logs, and stack traces generated during Go application execution.
- Correlate panic events with affected services, execution paths, and deployment changes to identify root causes.
- Identify recurring failures caused by concurrency conflicts, dependency issues, and configuration problems.
- Detect hidden runtime failures affecting service stability and transaction processing.
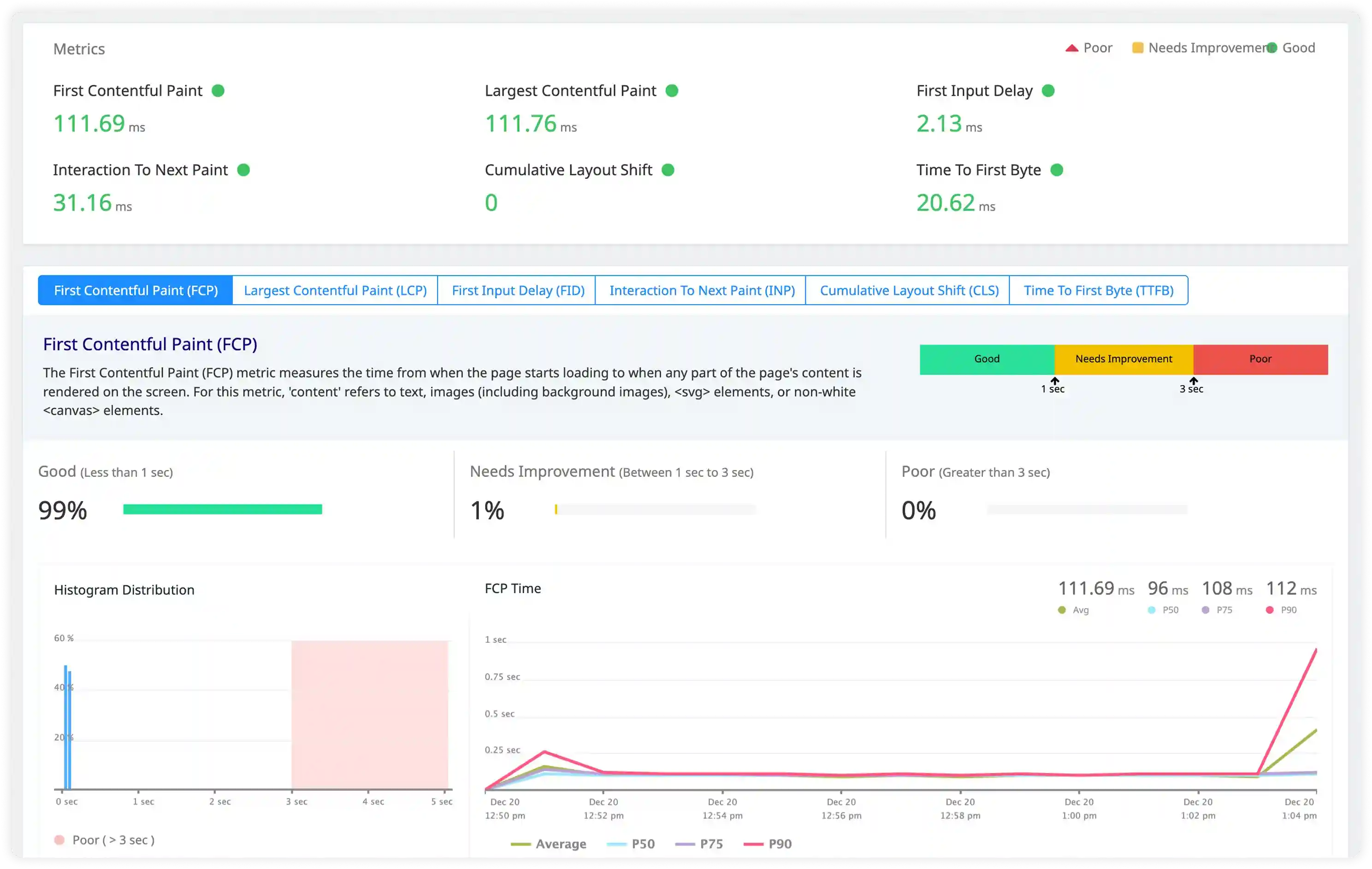
Performance and Resource Behavior
- Analyze slow execution logs, resource contention messages, and concurrency-related timing signals affecting performance.
- Correlate execution behavior with database operations, API dependencies, and workload latency across services.
- Identify excessive logging impacting CPU usage, memory utilization, and I/O performance.
- Detect performance degradation through abnormal execution timing and irregular log volume patterns.
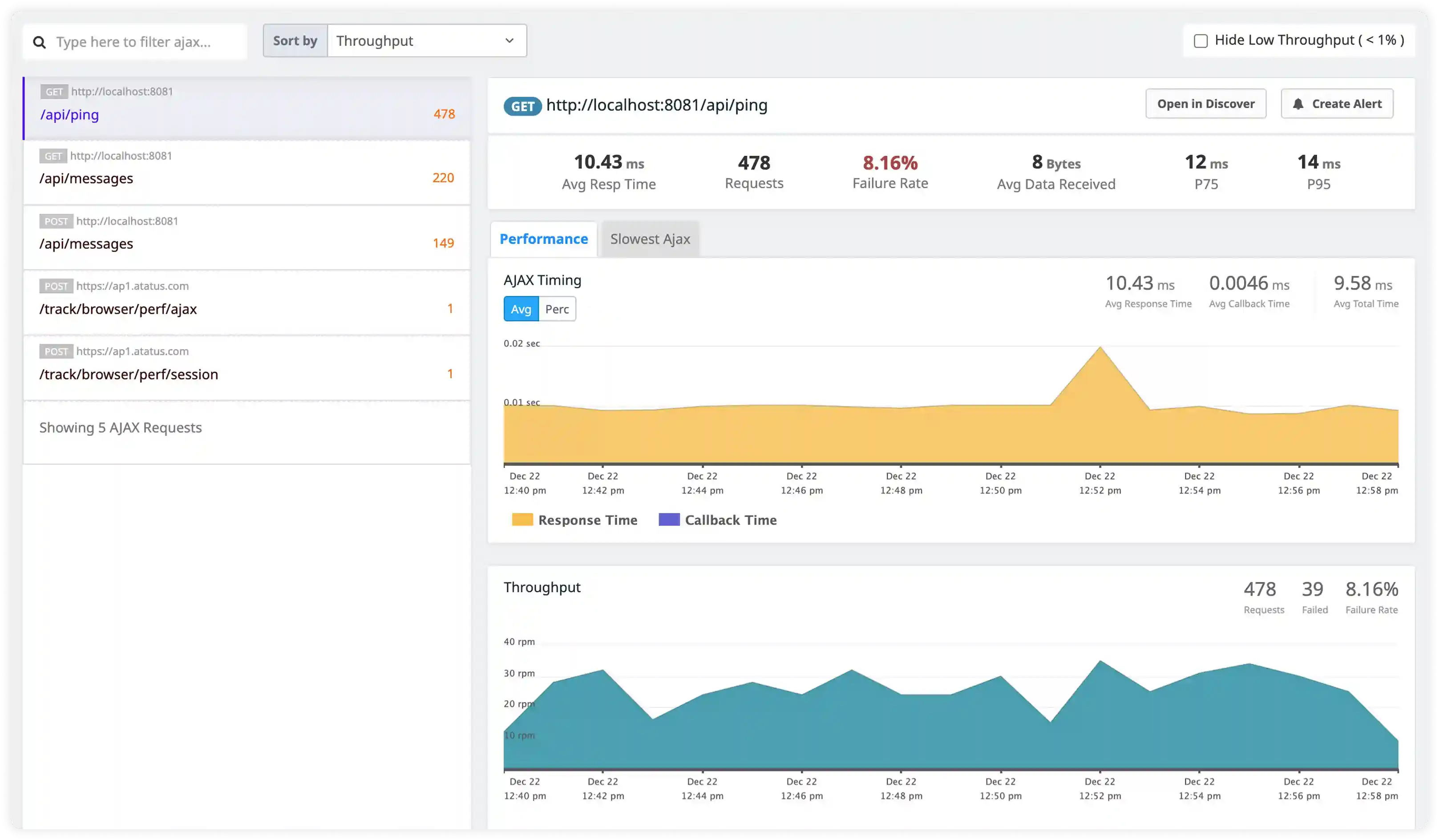
Security and Operational Monitoring
- Track authentication failures, suspicious traffic patterns, and unauthorized access attempts captured in Go service logs.
- Identify abnormal behavior across services indicating misuse, attacks, or operational risks.
- Correlate application logs with infrastructure activity for incident investigation and operational visibility.
- Detect reliability and security incidents affecting Go workloads using centralized log insights.
Why choose Atatus for Golang logs monitoring?
Built for Go services
Atatus ingests structured and unstructured Go logs from production microservices without code changes.
Goroutine-aware context
Atatus preserves request and goroutine context to simplify concurrent execution tracing.
Structured log parsing
Atatus extracts fields like request IDs and service metadata for precise log analysis.
Panic and error grouping
Atatus indexes and groups Go panics and errors to accelerate root cause analysis.
High-volume ingestion
Atatus handles large log streams from high-throughput Go services without performance impact.
Centralized visibility
Atatus aggregates logs across containers, Kubernetes, and cloud environments in one place.
Unified Observability for Every Engineering Team
Atatus adapts to how engineering teams work across development, operations, and reliability.
Developers
Trace requests, debug errors, and identify performance issues at the code level with clear context.
DevOps
Track deployments, monitor infrastructure impact, and understand how releases affect application stability.
Release Engineer
Measure service health, latency, and error rates to maintain reliability and reduce production risk.