Kubernetes Logs Monitoring & Observability
Explore the nuances of Kubernetes Logging, offering a comprehensive approach to efficiently troubleshoot Kubernetes, trace issues, and optimize cluster performance.
Monitor Kubernetes logs across clusters, nodes, and workloads
Collect container stdout and stderr
Capture logs emitted to stdout and stderr by containers running in Kubernetes pods, including application output and runtime errors.
Aggregate pod and namespace logs
Organize logs by pod, namespace, workload, and label selectors to simplify troubleshooting in multi-tenant Kubernetes clusters.
Track pod lifecycle events
Ingest logs related to pod creation, restarts, crashes, and termination to analyze deployment and stability issues.
Monitor node-level system logs
Collect kubelet and container runtime logs from worker nodes to diagnose scheduling failures, image pull errors, and resource pressure.
Debug CrashLoopBackOff scenarios
Analyze container startup logs and failure messages to identify configuration errors and repeated pod restarts.
Correlate logs with Kubernetes metadata
Enrich log entries with Kubernetes context such as pod name, node, namespace, and deployment to speed up root cause analysis.
Observe control plane log signals
Capture logs from Kubernetes control plane components to investigate cluster-level issues and API server errors.
Handle high-volume cluster logging
Centralize Kubernetes logs from large clusters while maintaining query performance during traffic spikes and rolling deployments.
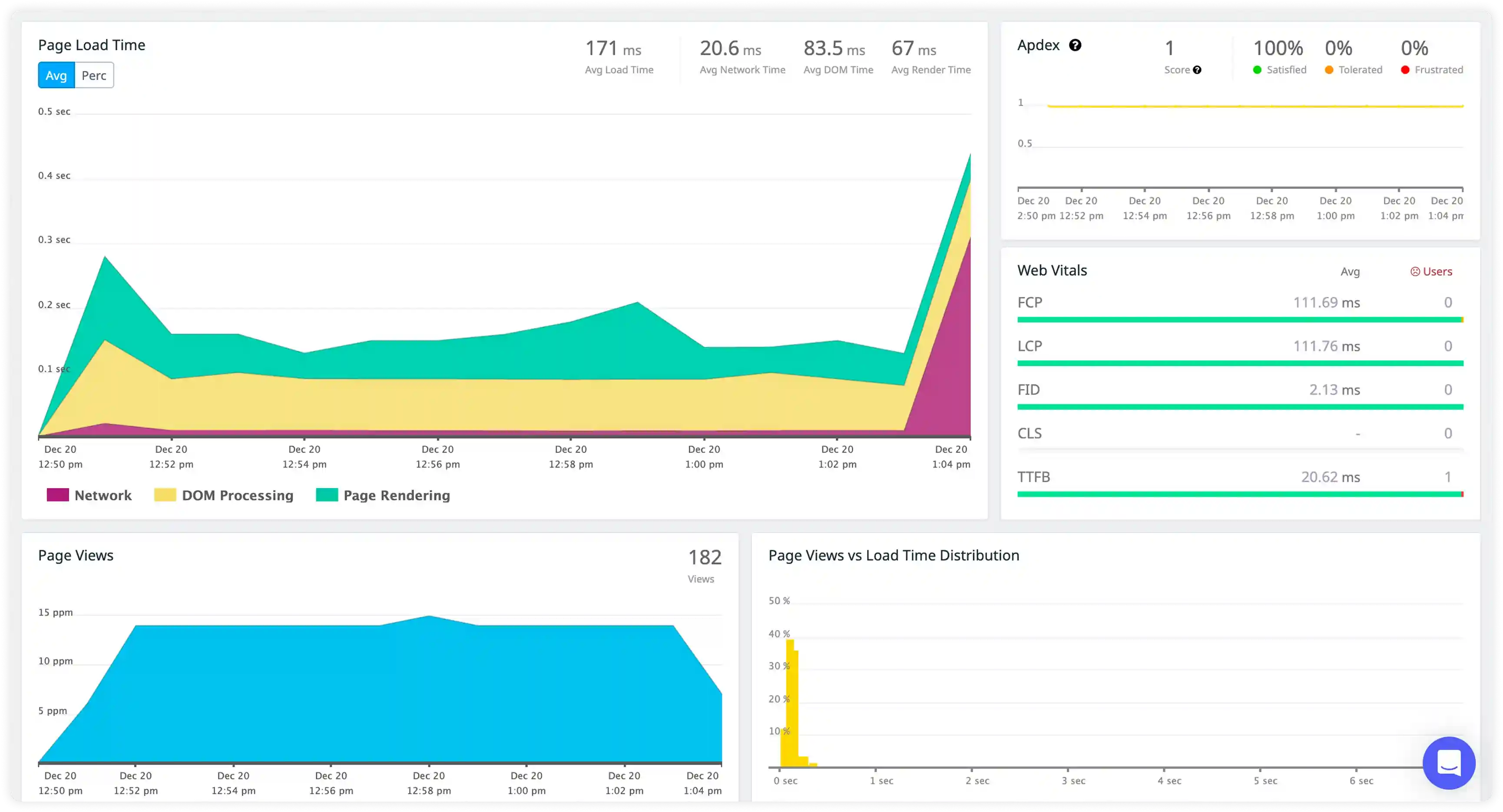
Pod and Container Lifecycle Visibility
- Track log generation across pod creation, container start and stop events, and workload execution to understand lifecycle behavior in Kubernetes environments.
- Correlate logs with deployment changes, scaling events, and scheduling decisions across cluster workloads.
- Identify pod restarts, crash loops, and container failures affecting workload stability.
- Detect disruptions in workload orchestration and container lifecycle management impacting service availability.
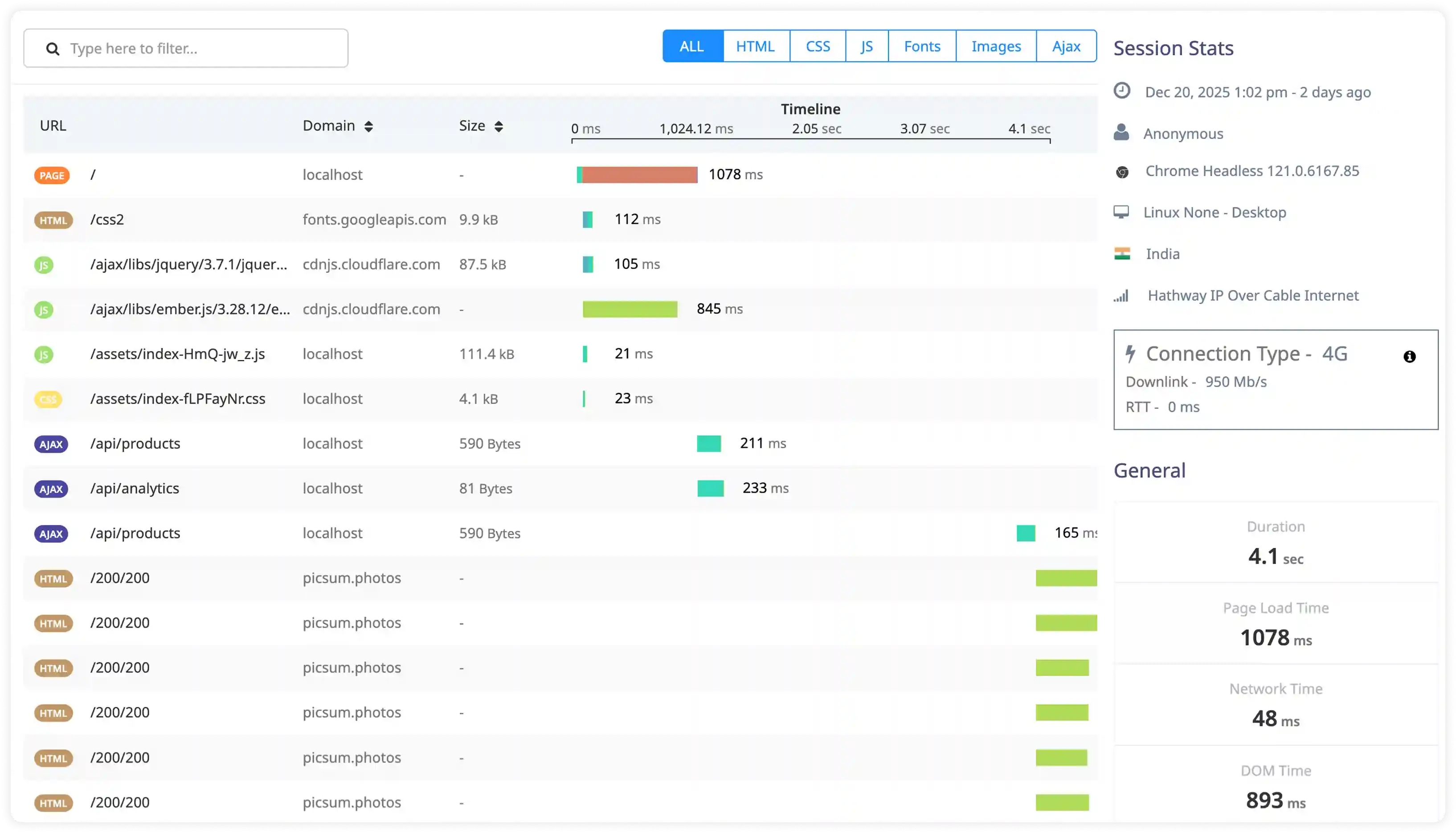
Node, Scheduler, and Control Plane Diagnostics
- Capture logs from kubelet, scheduler, and control plane components to monitor cluster operations and workload placement.
- Correlate node-level events with pod scheduling failures, resource constraints, and infrastructure issues.
- Identify recurring failures in cluster coordination, node health, and workload orchestration.
- Detect hidden infrastructure issues affecting cluster stability and workload execution.
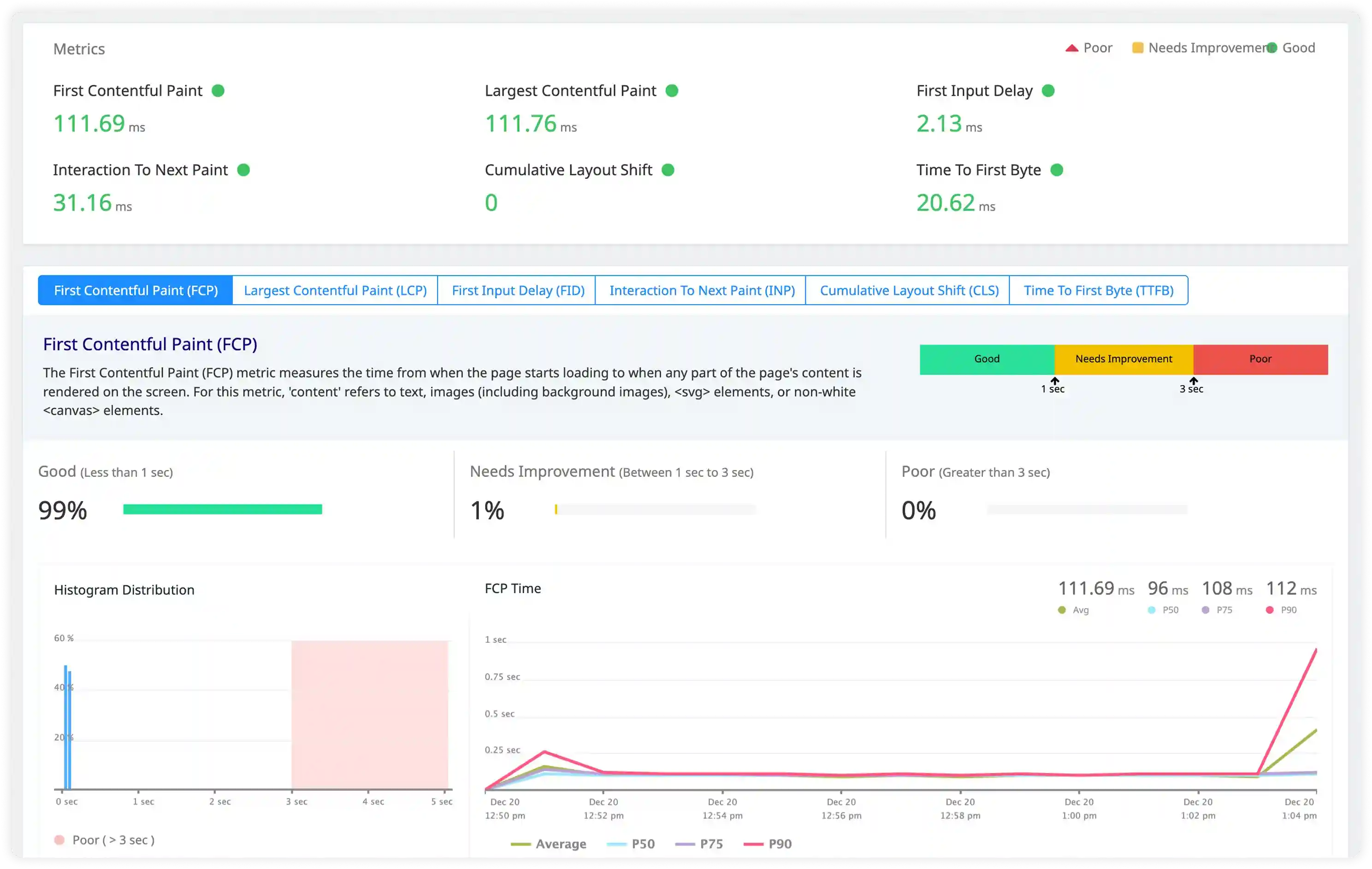
Workload Performance and Resource Signals
- Analyze execution logs, resource warnings, and workload timing signals across pods and containers.
- Correlate log activity with CPU usage, memory consumption, and network behavior during workload execution.
- Identify excessive logging from containers increasing storage usage and processing overhead.
- Detect performance degradation through abnormal workload behavior and irregular log volume patterns.
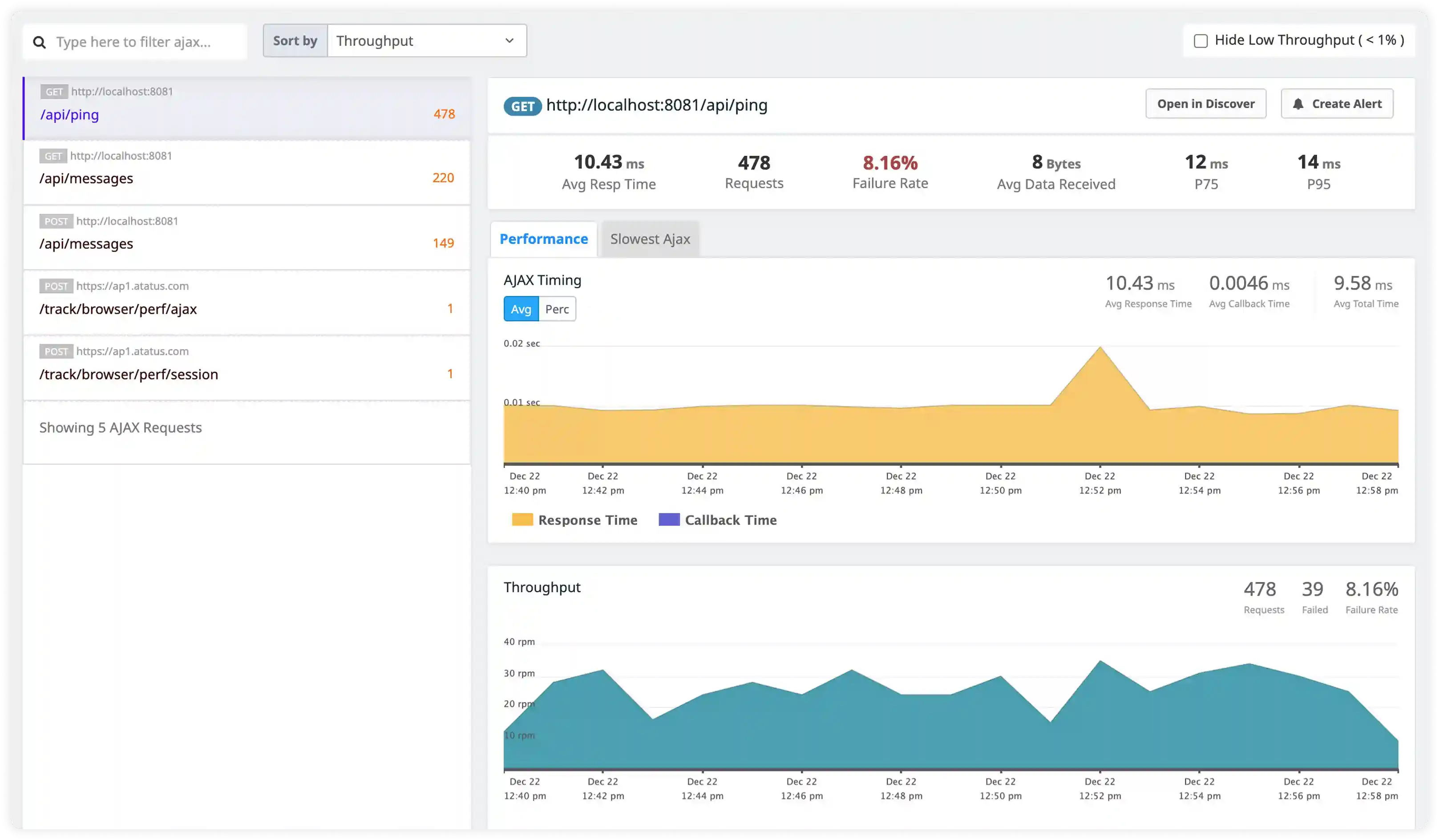
Security and Cluster Activity Monitoring
- Track unauthorized access attempts, RBAC violations, and suspicious cluster activity captured in logs.
- Identify abnormal traffic behavior and misuse affecting Kubernetes environments.
- Correlate application and infrastructure logs for incident investigation across distributed services.
- Detect operational and security incidents affecting cluster reliability using centralized log insights.
Why choose Atatus for Kubernetes logs monitoring?
Production-ready visibility into Kubernetes workloads, pod lifecycle events, and cluster operations
Kubernetes-native log collection
Designed to collect logs directly from Kubernetes pods and nodes without requiring changes to application containers.
Deep workload context
Automatically associates logs with Kubernetes metadata such as namespaces, deployments, nodes, and labels.
Faster incident investigation
Correlates pod restarts, container crashes, and deployment events across logs to reduce mean time to resolution.
Scales with growing clusters
Handles high log volumes generated by large Kubernetes clusters and dynamic workloads without performance degradation.
Supports modern Kubernetes environments
Works across managed Kubernetes services, self-hosted clusters, and hybrid infrastructure setups.
Built for SRE and platform teams
Provides the log visibility required by platform engineers to operate and maintain reliable Kubernetes infrastructure.
Unified Observability for Every Engineering Team
Atatus adapts to how engineering teams work across development, operations, and reliability.
Developers
Trace requests, debug errors, and identify performance issues at the code level with clear context.
DevOps
Track deployments, monitor infrastructure impact, and understand how releases affect application stability.
Release Engineer
Measure service health, latency, and error rates to maintain reliability and reduce production risk.