Node.js Logs Monitoring & Observability
Effortlessly track Node.js logs, gaining instant insights into errors and refining logging for a more efficient and reliable application.
Achieve full visibility into Node.js application logs across Express, NestJS, and distributed runtime environments
Native Node.js stream log capture
Instrument process.stdout/stderr streams and async logger calls to capture unhandledRejection events, assertion failures, and module load errors from production Node.js processes.
Async operation log correlation
Parse structured logs from Winston, Pino transports, and custom async_hooks domains. Track Promise chain failures, EventEmitter memory leaks, and callback hell scenarios across distributed clusters.
Node.js cluster & worker insights
Monitor logs across primary/worker processes, PM2 instance groups, and Docker container fleets. Surface inter-process communication failures and load balancer health issues from Node.js runtime logs.
Event loop delay & heap analysis
Detect event loop lag warnings, V8 garbage collection pauses, heapdump triggers, and max-old-space-size exceeded conditions logged by Node.js diagnostics.
Database driver & queue failures
Capture Mongoose connection drops, Redis pub/sub disconnects, BullMQ job timeouts, and Prisma query failures embedded in Node.js application logs with full stack context.
Source map error resolution
Transform minified production stack traces back to original TypeScript/ESM source files. Link Node.js log entries directly to controllers, middleware functions, and service implementations.
Dependency version conflict alerts
Track npm audit warnings, peer dependency mismatches, and package-lock.json drift logged during Node.js startup and hot reload cycles across CI/CD deployments.
Microservices inter-service tracing
Correlate logs across NestJS microservices, Express API gateways, and GraphQL resolvers using traceparent headers and OpenTelemetry context propagation standards.
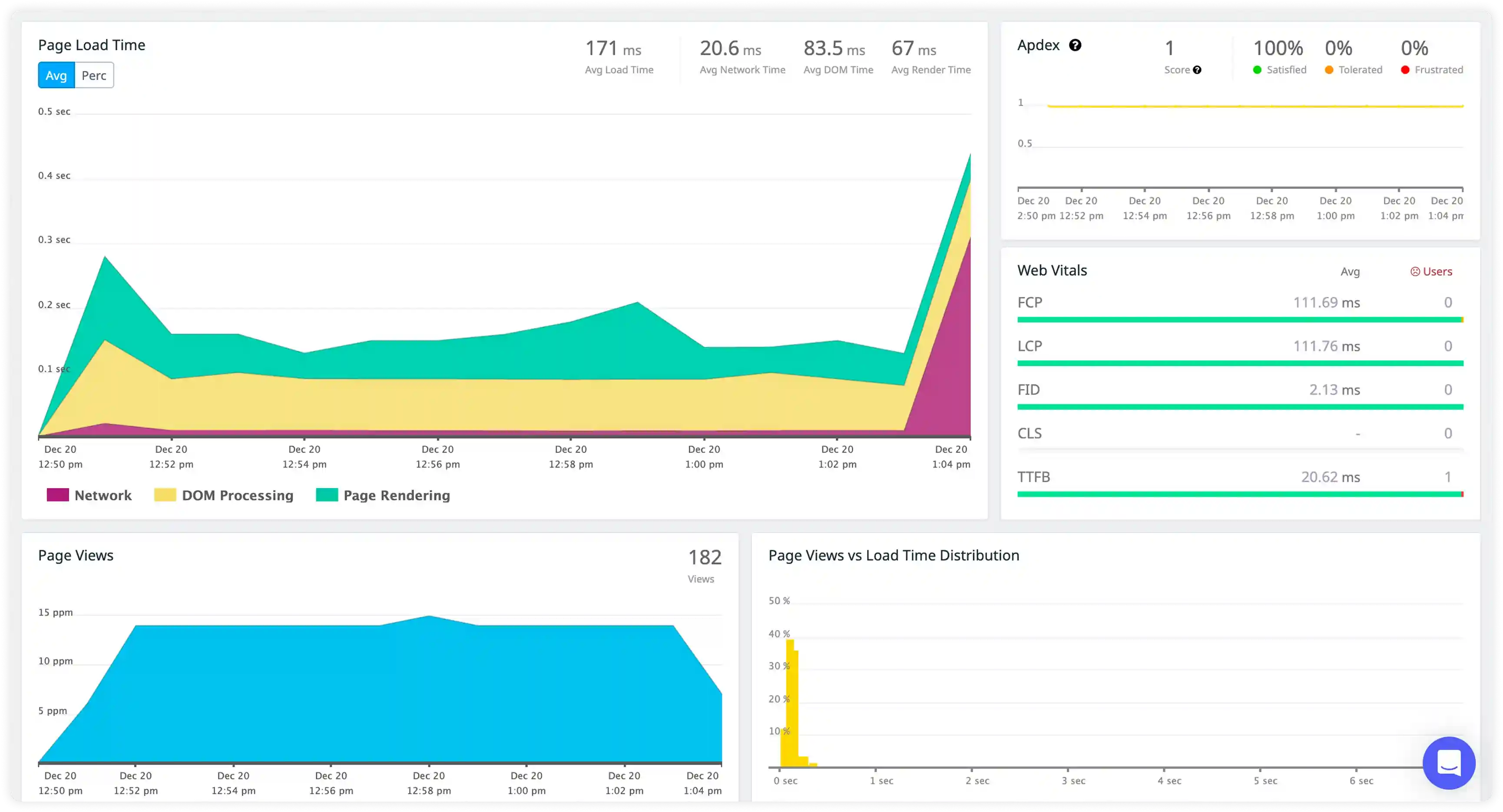
Request and Asynchronous Execution Flow
- Track log generation across API requests, middleware execution, and asynchronous job processing to understand request handling behavior in Node.js services.
- Correlate log entries with request IDs, service interactions, and execution paths to trace event-driven workflows across the application.
- Identify delays and failures in asynchronous execution, callback chains, and background job processing affecting service responsiveness.
- Detect breakdowns in request routing, middleware logic, and handler execution impacting API reliability.
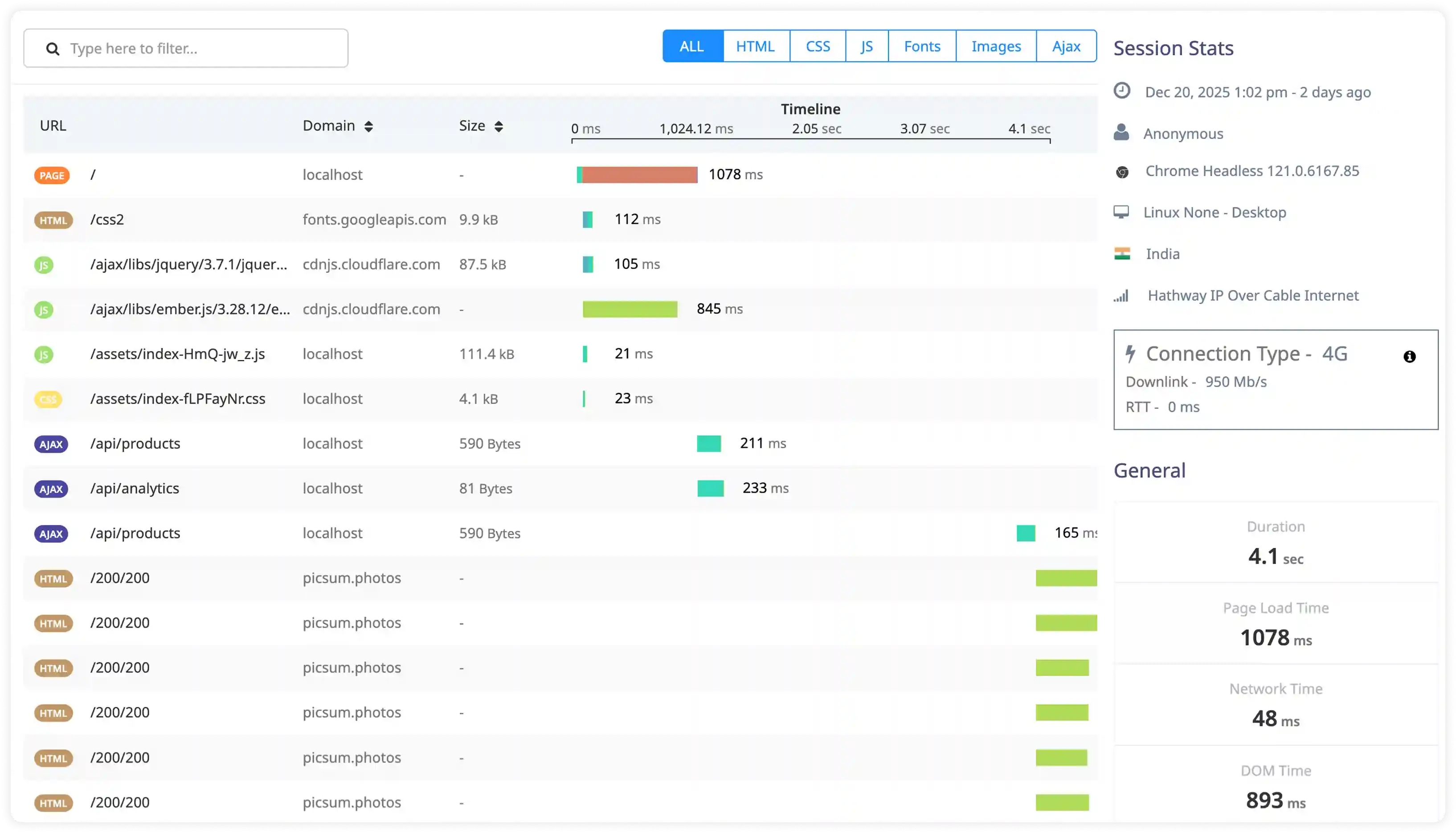
Runtime Errors and Promise Rejection Tracking
- Capture runtime exceptions, unhandled promise rejections, and application errors generated during execution.
- Correlate stack traces with impacted endpoints, service interactions, and deployment changes to identify failure sources.
- Identify recurring runtime failures caused by dependency issues, memory leaks, or asynchronous execution conflicts.
- Detect silent runtime failures affecting API stability and transaction completion.
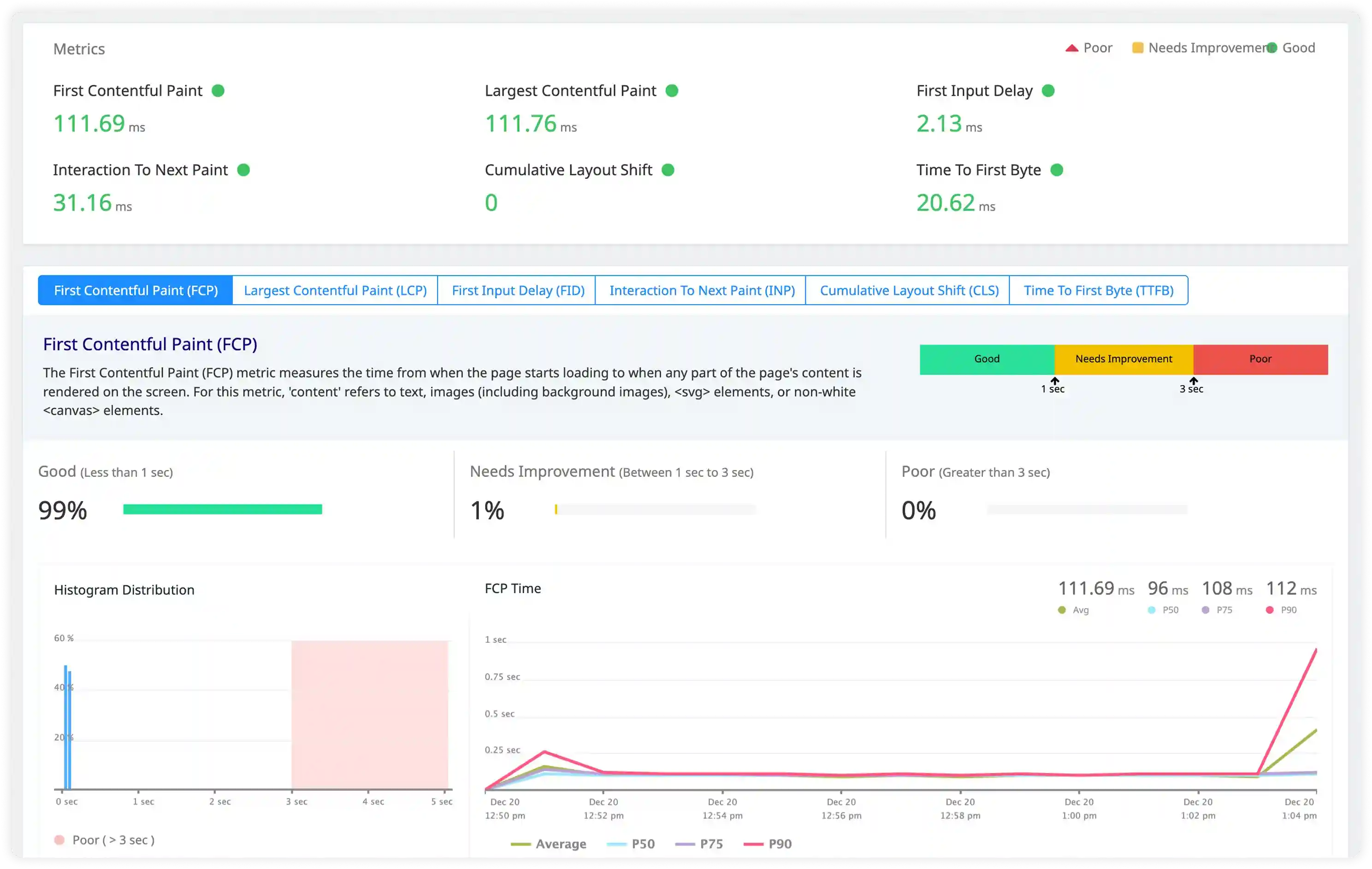
Event Loop and Execution Performance Signals
- Analyze slow request logs, event loop delays, and execution warnings affecting responsiveness.
- Correlate Node.js execution behavior with database operations, external APIs, and service-to-service communication latency.
- Identify excessive logging from middleware, background workers, and asynchronous tasks increasing CPU and I/O overhead.
- Detect performance degradation through irregular execution timing and sudden log volume changes.
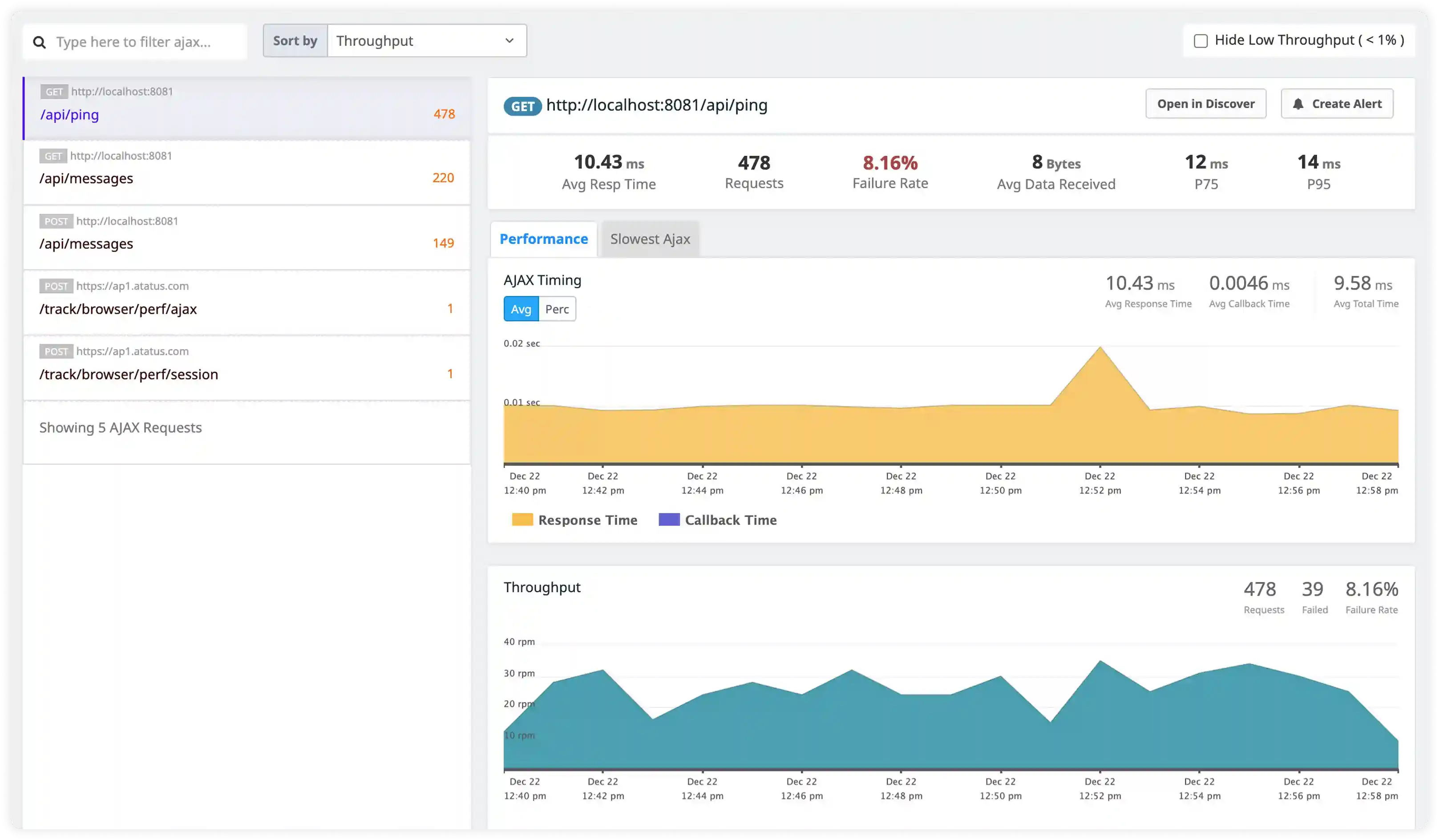
Security and API Access Monitoring
- Track authentication failures, rate-limit violations, and unauthorized API access attempts captured in logs.
- Identify suspicious traffic behavior, misuse patterns, and abnormal request activity affecting service stability.
- Correlate logs across microservices to investigate cascading failures and operational disruptions.
- Detect incident patterns and response gaps using centralized Node.js log visibility.
Why Choose Atatus for Node.js Logs Monitoring?
Built for Node.js scale
Atatus ingests and structures Pino and Winston logs automatically for high-traffic JavaScript applications.
Zero-config log parsing
Atatus detects popular Node.js log libraries without requiring code changes or reconfiguration.
Unified cluster visibility
Atatus combines logs across PM2 clusters, containers, and Kubernetes pods into a single timeline.
Non-blocking ingestion
Atatus forwards logs asynchronously to prevent backpressure during traffic spikes.
Minimal performance impact
Atatus maintains event loop responsiveness even under heavy concurrent workloads.
Cost-efficient retention
Atatus preserves critical Node.js logs long-term without runaway storage costs.
Unified Observability for Every Engineering Team
Atatus adapts to how engineering teams work across development, operations, and reliability.
Developers
Trace requests, debug errors, and identify performance issues at the code level with clear context.
DevOps
Track deployments, monitor infrastructure impact, and understand how releases affect application stability.
Release Engineer
Measure service health, latency, and error rates to maintain reliability and reduce production risk.