Python Logs Monitoring & Observability
Effortlessly track Python logs, gaining instant insights into errors and refining logging for a more efficient and reliable application.
Monitor Python application logs across Django, Flask, FastAPI, and production servers
Centralize Python logging output
Collect logs emitted via the Python logging module, structlog, and framework-level loggers from Django, Flask, and FastAPI applications into a unified log stream.
Parse structured and contextual logs
Extract fields from JSON logs, logger adapters, and contextual variables such as request IDs, user context, and correlation keys injected at runtime.
Trace request lifecycle events
Correlate logs generated during request handling, middleware execution, ORM queries, and response processing to analyze slow endpoints and request bottlenecks.
Detect runtime exceptions
Capture uncaught exceptions, stack traces, and traceback logs raised by Python applications to identify logic errors and failure points.
Preserve async execution context
Maintain request and trace context across asynchronous request handling and background processing in Python applications.
Map errors to source modules
Resolve stack traces to Python modules, functions, and line numbers to quickly locate the origin of runtime failures in application code.
Monitor dependency and import issues
Collect startup and runtime logs that expose missing packages, version conflicts, and import resolution failures in virtual environments.
Observe worker and process behavior
Track logs generated by multi-process Python runtimes such as Gunicorn, uWSGI, and Celery workers to analyze restarts, crashes, and execution issues.
Application Execution and Workflow Logging
- Track log generation across web requests, background workers, and scheduled jobs to understand Python application execution behavior.
- Correlate log entries with function calls, service interactions, and workflow steps to trace execution across application components.
- Identify execution failures in task processing, script execution, and service handling affecting application continuity.
- Detect disruptions in job queues, background processing, and runtime workflows impacting system reliability.
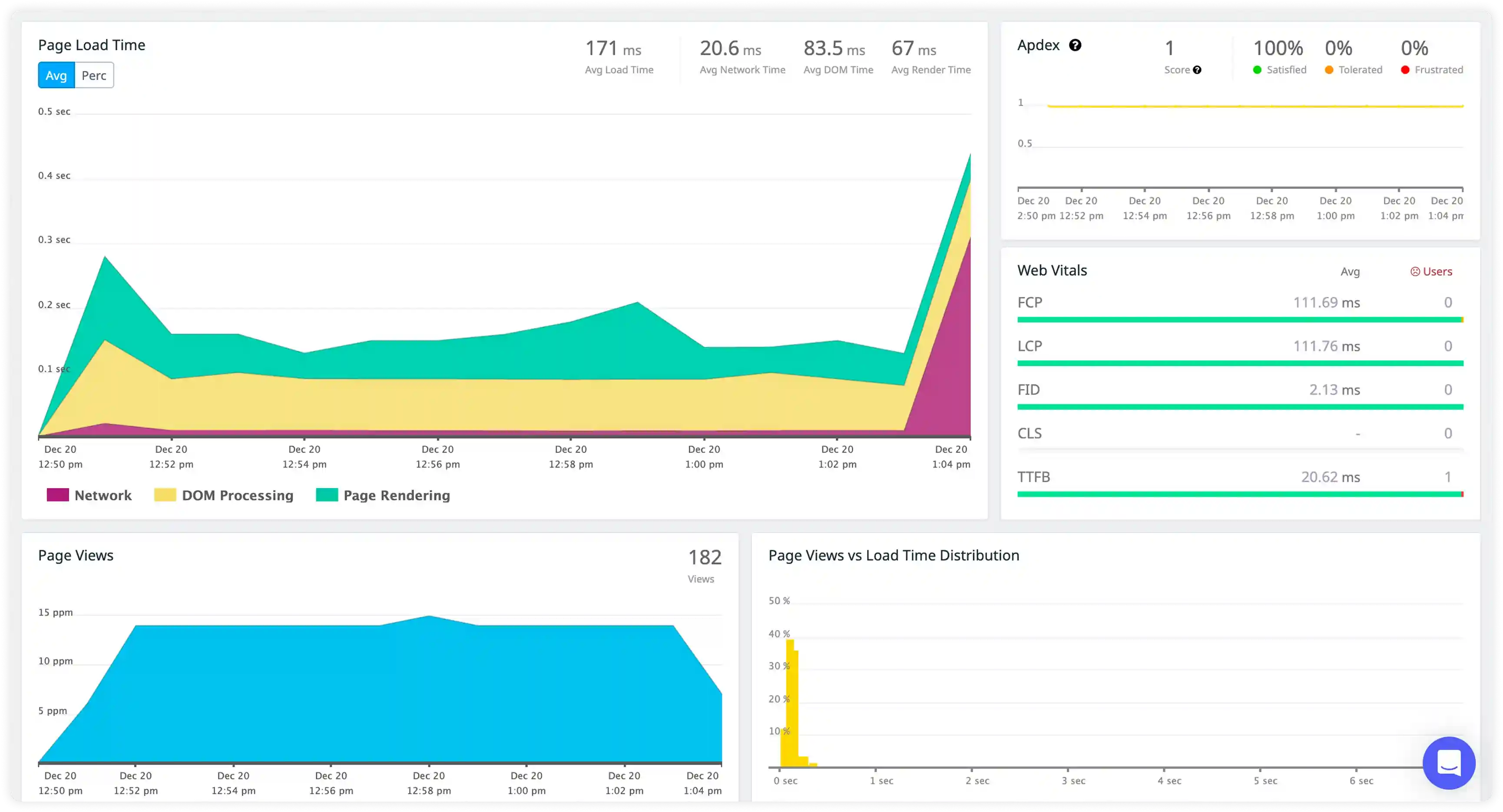
Exception and Runtime Failure Tracking
- Capture Python exceptions, stack traces, and runtime errors generated during application execution.
- Correlate exception logs with impacted services, workflows, and deployment changes to identify failure sources.
- Identify recurring failures caused by dependency issues, environment misconfigurations, and logic regressions.
- Detect silent runtime failures affecting application stability and process completion.
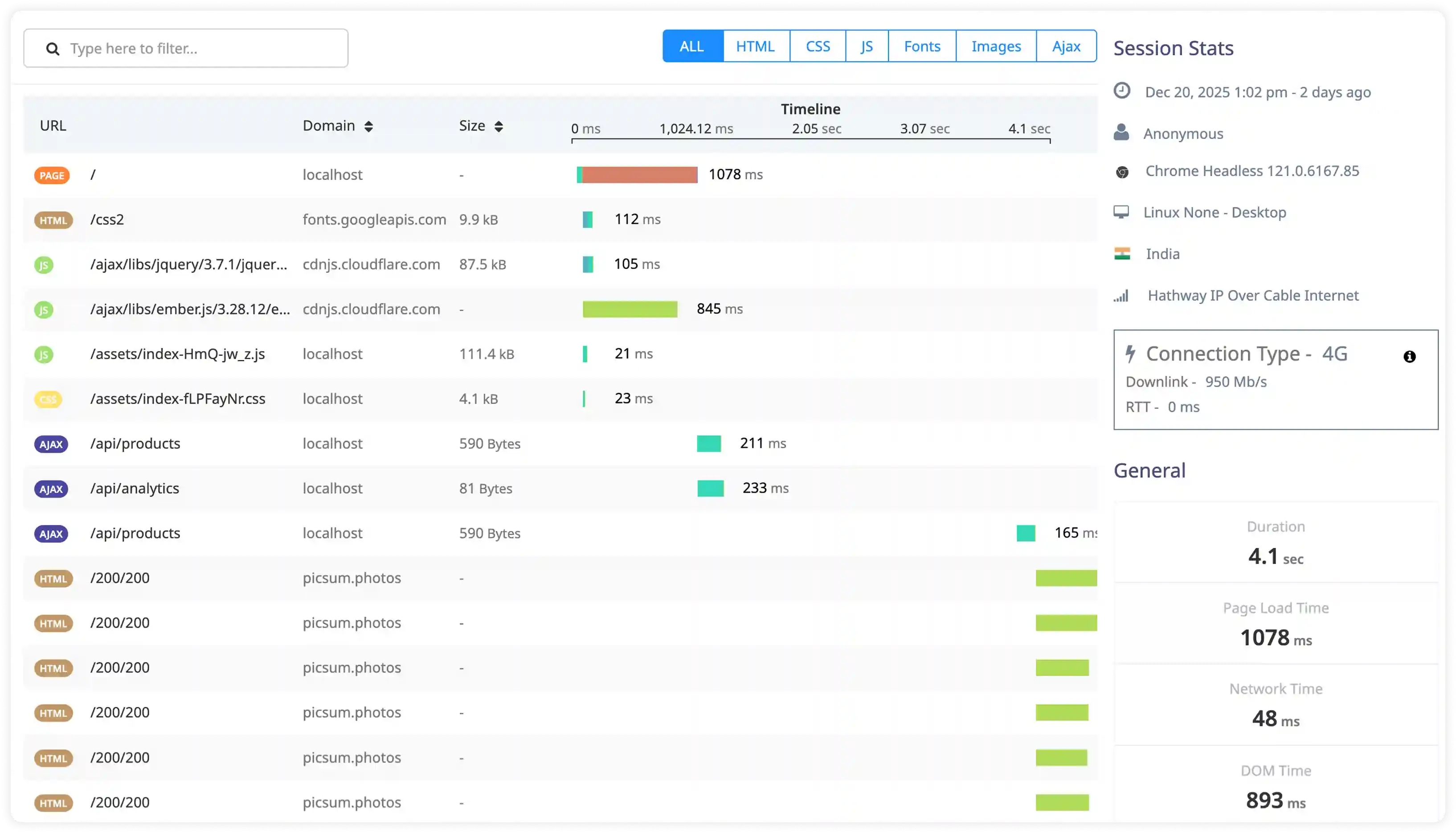
Execution Performance and Resource Signals
- Analyze slow execution logs, timeout warnings, and resource-related messages affecting Python workload performance.
- Correlate execution behavior with database queries, API calls, and background task latency across services.
- Identify excessive logging from loops, worker processes, and scheduled jobs increasing runtime overhead.
- Detect performance degradation through abnormal execution timing, latency spikes, and irregular log patterns.
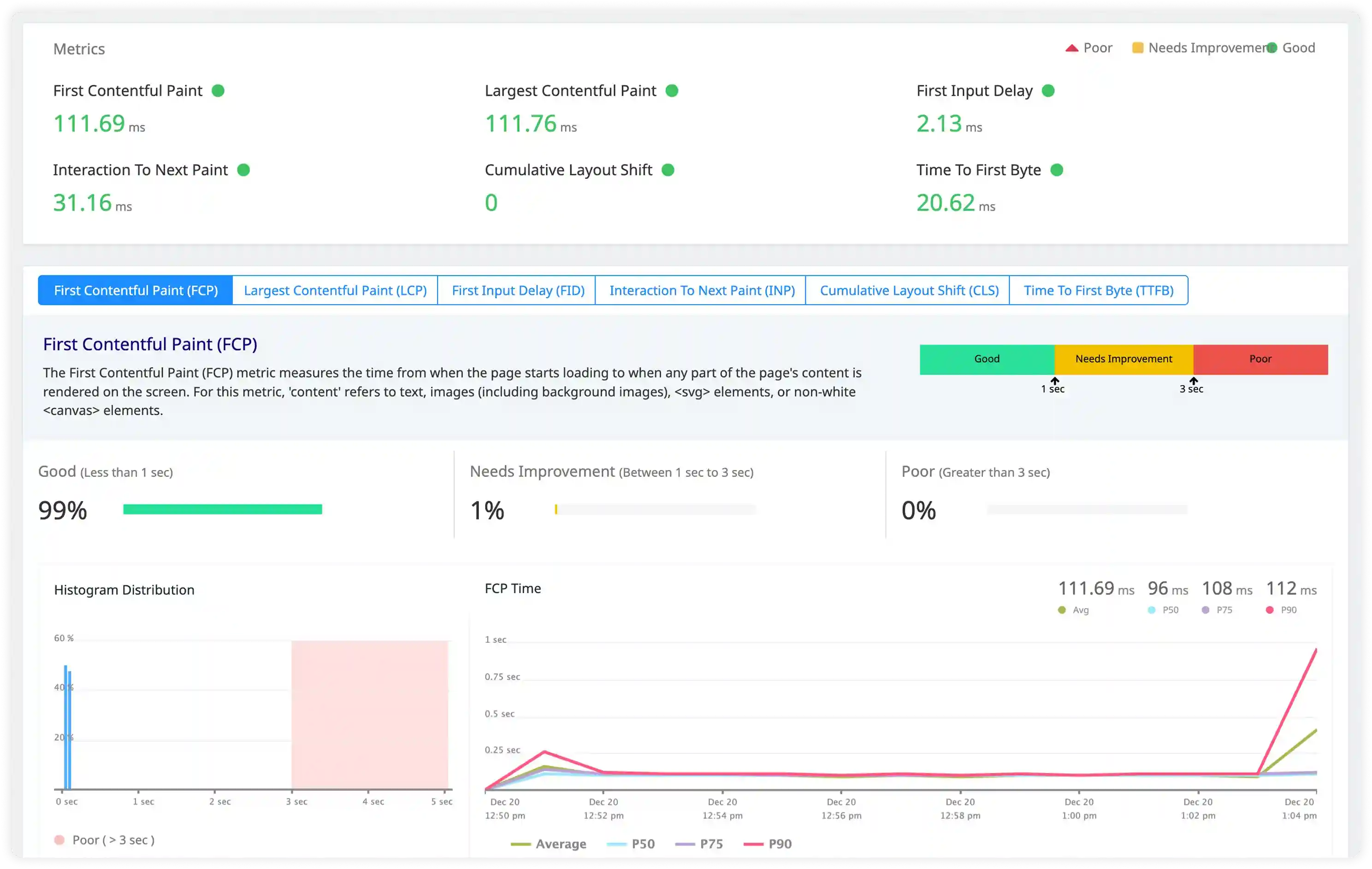
Security and Operational Monitoring
- Track authentication failures, access violations, and suspicious activity captured in Python application logs.
- Identify abnormal usage behavior, injection attempts, and unauthorized interactions affecting services.
- Correlate application logs with infrastructure activity for incident investigation and operational visibility.
- Detect security and reliability incidents affecting Python workloads using centralized log insights.
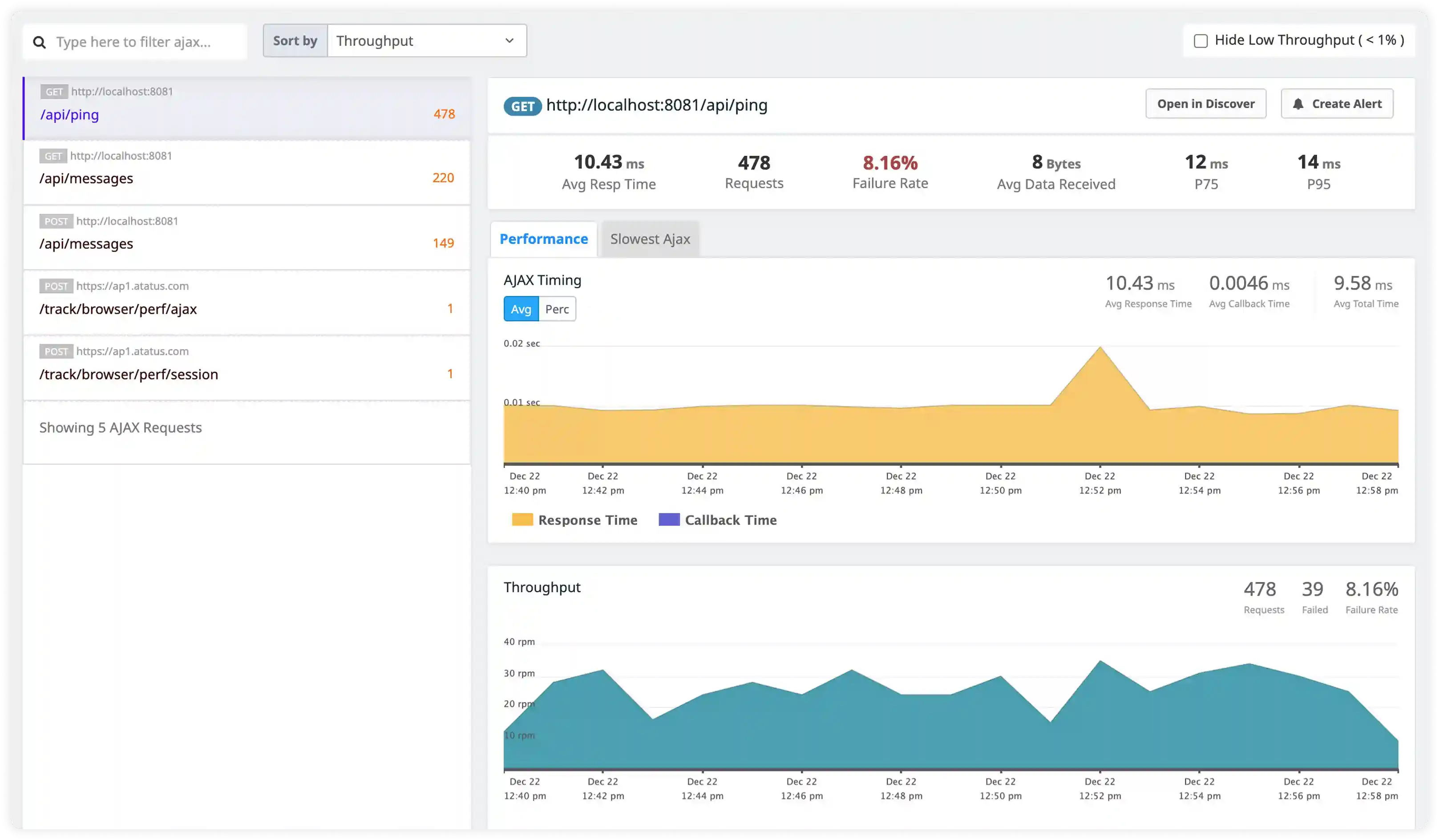
Why Choose Atatus for Python Logs Monitoring?
Native logging support
Atatus integrates seamlessly with Python logging frameworks and structured log libraries without invasive changes.
Framework-aware correlation
Atatus connects logs from Django, Flask, and FastAPI layers to reflect real request execution paths.
Async worker visibility
Atatus captures logs from asyncio tasks and background workers with full execution context.
Exception diagnostics
Atatus indexes and groups Python tracebacks to accelerate root cause analysis.
Environment-wide aggregation
Atatus centralizes logs across containers, VMs, and orchestrated environments.
Secure log retention
Atatus stores application and audit logs with configurable retention for production compliance.
Unified Observability for Every Engineering Team
Atatus adapts to how engineering teams work across development, operations, and reliability.
Developers
Trace requests, debug errors, and identify performance issues at the code level with clear context.
DevOps
Track deployments, monitor infrastructure impact, and understand how releases affect application stability.
Release Engineer
Measure service health, latency, and error rates to maintain reliability and reduce production risk.