Purpose-built Observability for Platform Engineering Teams
One unified observability layer across infrastructure, services, logs, traces, and deployments, so your team ships faster and debugs in minutes, not hours.
73%
Faster mean time to root cause
4x
More deploys per week, same team size
91%
Reduction in production incidents post-adoption
8mins
Average MTTR for teams on Atatus
Most platform teams aren't lacking effort. They're lacking the right signal at the right time
"A deploy went out and something's slow, but I can't tell which service changed." Without deployment context tied to performance data, every incident starts with "who deployed what and when?", not with a fix.
"Debugging a latency spike in our microservices takes the whole team half a day." Without end-to-end tracing across 12 services and databases, you're reading tea leaves, not data.
"We're maintaining four separate tools just to get a complete picture of production." APM here. Logs there. Infra metrics elsewhere. When tools don't talk, critical correlations get missed entirely.
"Every release feels like a leap of faith. We have no real-time signal on whether it's healthy." When you can't see deploy impact on error rates and latency the moment it goes live, shipping is a prayer, not a decision.
Connect deploys, metrics, traces, and logs instantly
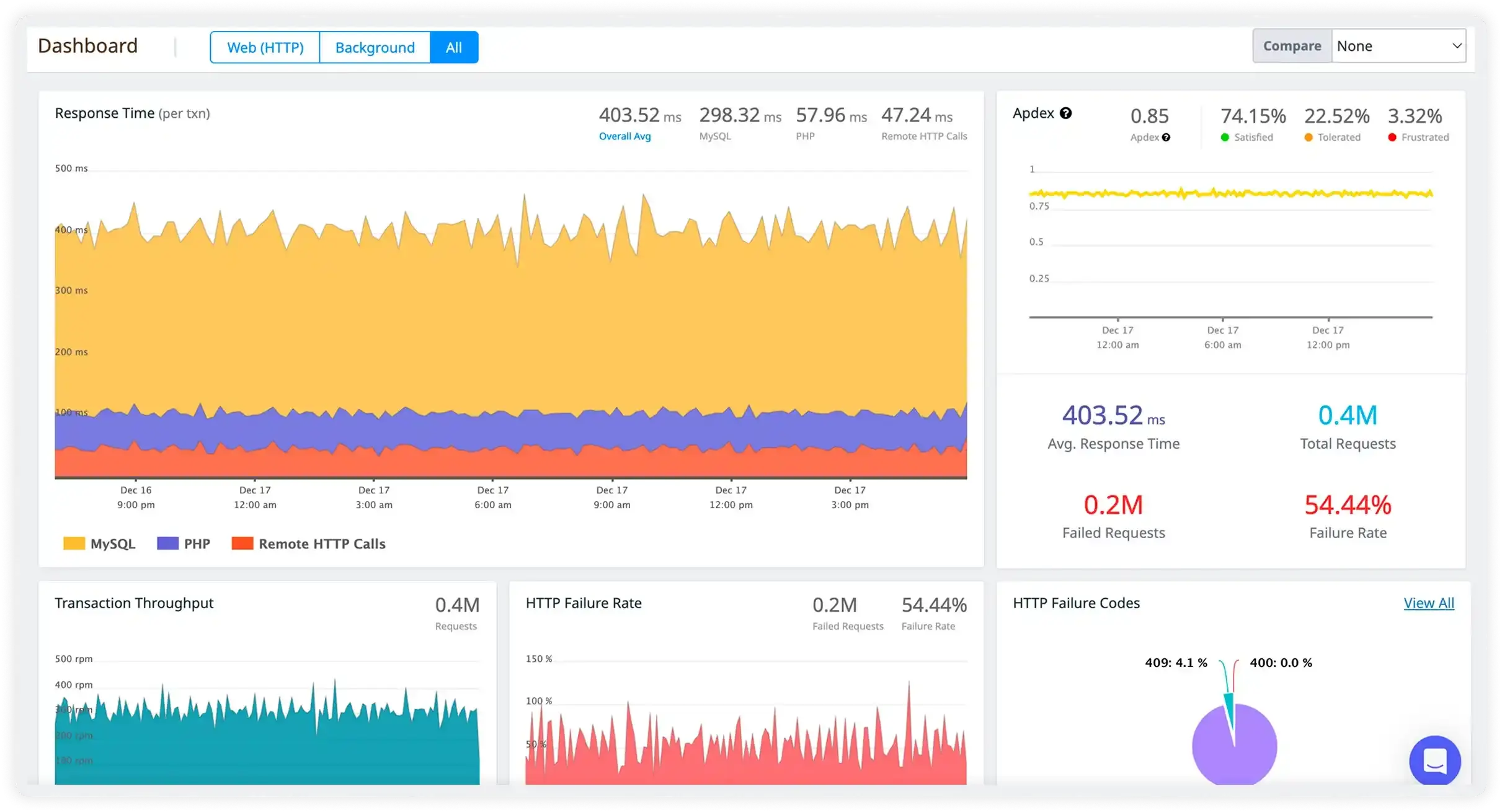
From Signal to Root Cause in One Place
Atatus automatically correlates logs, metrics, distributed traces, and deployment events, giving your team a real-time, connected view of everything happening in production. When an anomaly surfaces, you already have the deployment that caused it, the service that's affected, and the log line that explains it on one screen.
- 5-min agent setup
- Full-fidelity, no sampling
- Auto-instrumented
Built for the problems you're solving today.
Standardize Observability Across All Teams
Define and enforce one observability standard across every squad, service, and language. Auto-instrumentation for 20+ runtimes means developers get production insights on day one without writing telemetry code.
Improve Release Confidence for Every Squad
Give every team a deployment health score the moment their release goes live. Error trends, latency shifts, and user impact appear in real time turning every deploy into a data-driven decision.
Reduce MTTR from Hours to Minutes
When incidents happen, the first 10 minutes are everything. Give your on-call engineer the deployment, the service, the trace, and the log line on one screen. Fix the problem, not the puzzle.
Manage Microservices at Scale Without Chaos
As your service mesh grows from 10 to 100 services, visibility can't scale manually. Auto-discovered service maps track inter-service latency and surface ripple effects before they cascade to users.
Accelerate Root Cause Analysis Across Systems
Quickly trace issues across services without jumping between tools. Correlate metrics, logs, and traces in one view so teams can identify root causes faster and reduce time spent debugging.
Ensure Reliability with Proactive Alerting
Stay ahead of issues with intelligent alerts based on real system behavior. Detect anomalies early, reduce noise, and ensure your teams act on what truly matters.
Plugs into your existing stack
No rip-and-replace. Connects to the tools your team already uses from cloud providers to CI/CD to alerting.
Not Just Monitoring. Platform Intelligence
The tools you've been using were built for developers. Atatus is built for the teams who build the platform those developers rely on.
Unified Tooling
Replace APM, log management, infra monitoring, and error tracking with one platform. One bill. One context. No gaps.
Dev-Platform Alignment
Shared dashboards between platform and product teams mean everyone speaks the same observability language in production.
AI-Powered Insights
Automated anomaly detection and deployment regression analysis, no manual threshold tuning or bespoke alert queries.
Lightweight Agents
Under 1% CPU at p99. eBPF-based infra monitoring with zero code changes. Auto-instrumentation deployed in minutes.
Replacing 4 tools with 1?
Teams migrating from Datadog + Splunk stacks report 60-70% cost reduction without losing visibility.
Unified Observability for Every Engineering Team
Atatus adapts to how engineering teams work across development, operations, and reliability.
Developers
Trace requests, debug errors, and identify performance issues at the code level with clear context.
DevOps
Track deployments, monitor infrastructure impact, and understand how releases affect application stability.
Release Engineer
Measure service health, latency, and error rates to maintain reliability and reduce production risk.
Powering better performance
for modern teams
Feedback from teams improving monitoring and debugging workflows
"Solid Product even better support", The integration path is incredibly simple/easy and the overall interface is very intuitive. That said, I had a handful of odd use cases that the support team was incredibly responsive in helping me work through.

Wes D
Site Reliability Engineer