Operational Logging for MongoDB Clusters
Track collection activity, oplog events, shard synchronization, and query performance signals.
Monitor MongoDB logs across standalone instances, replica sets, and sharded clusters
Analyze slow MongoDB operations
Inspect MongoDB slow query log entries to identify long-running commands, inefficient aggregation pipelines, and collection scans impacting database response time.
Track query execution behavior
Extract execution details such as command type, namespace, execution duration, keys examined, and documents scanned directly from MongoDB logs.
Monitor replication and elections
Follow replica set log events to detect primary elections, replication lag warnings, rollback activity, and heartbeat failures affecting availability.
Detect authentication failures
Capture MongoDB authentication and authorization log events to identify failed login attempts, role misconfigurations, and TLS handshake errors.
Observe storage engine activity
Analyze WiredTiger log messages to understand cache pressure, eviction behavior, checkpoint delays, and disk I/O contention.
Track index and schema changes
Monitor index creation, index removal, and schema-related log entries to understand changes that influence query execution patterns.
Identify runtime errors and warnings
Group MongoDB error codes, warning levels, and fatal events from logs to surface recurring database stability issues.
Correlate database logs with apps
Link MongoDB log events with application logs to trace database failures back to specific services, deployments, or request paths.
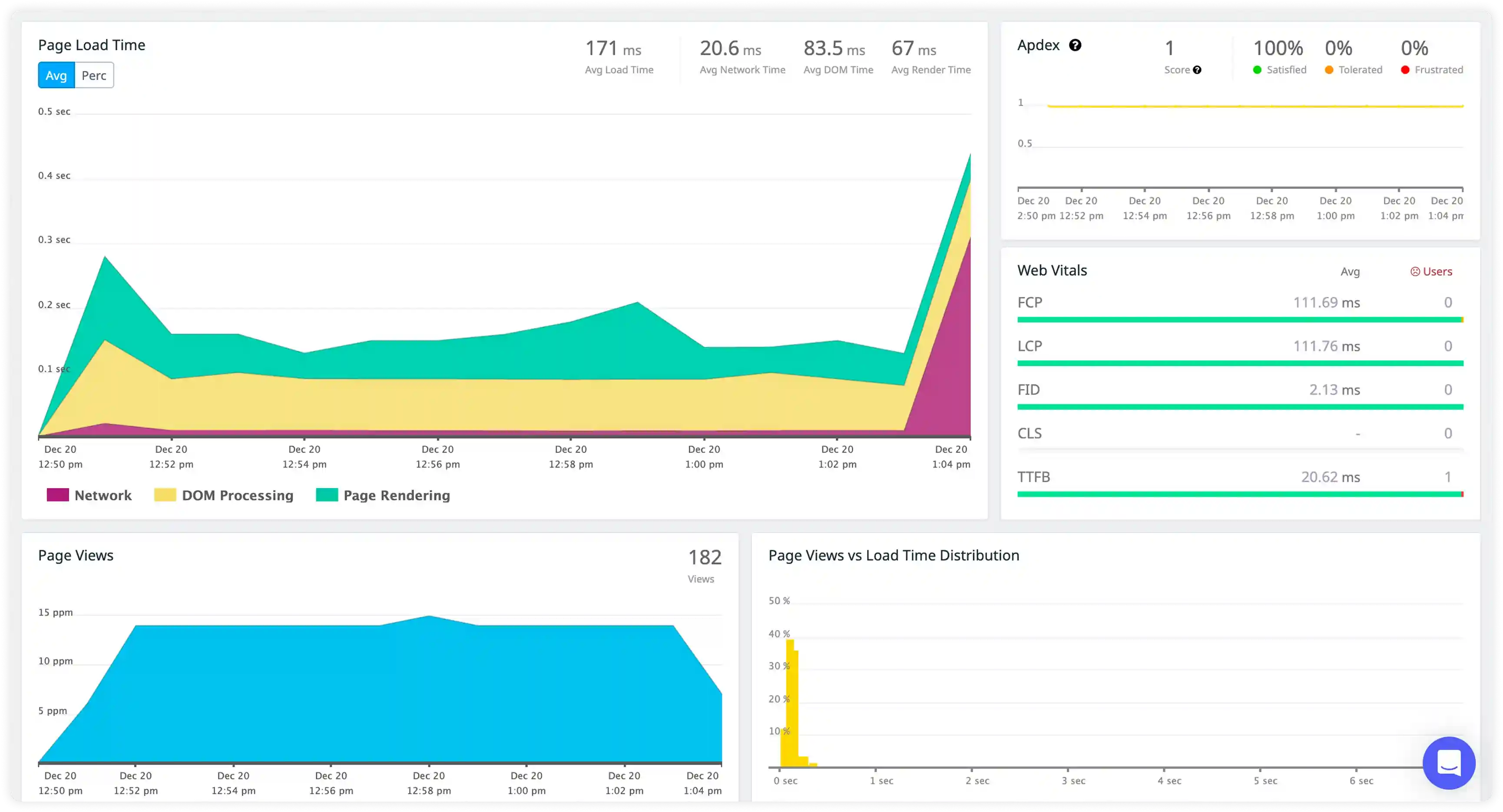
Query Operations and Collection Activity
- Track log generation across CRUD operations, aggregation pipelines, and collection-level activity to understand workload behavior in MongoDB environments.
- Correlate query logs with application requests and data access patterns to trace read and write execution flows.
- Identify failed operations, query timeouts, and write conflicts affecting database responsiveness.
- Detect disruptions in collection activity impacting data availability and application performance.
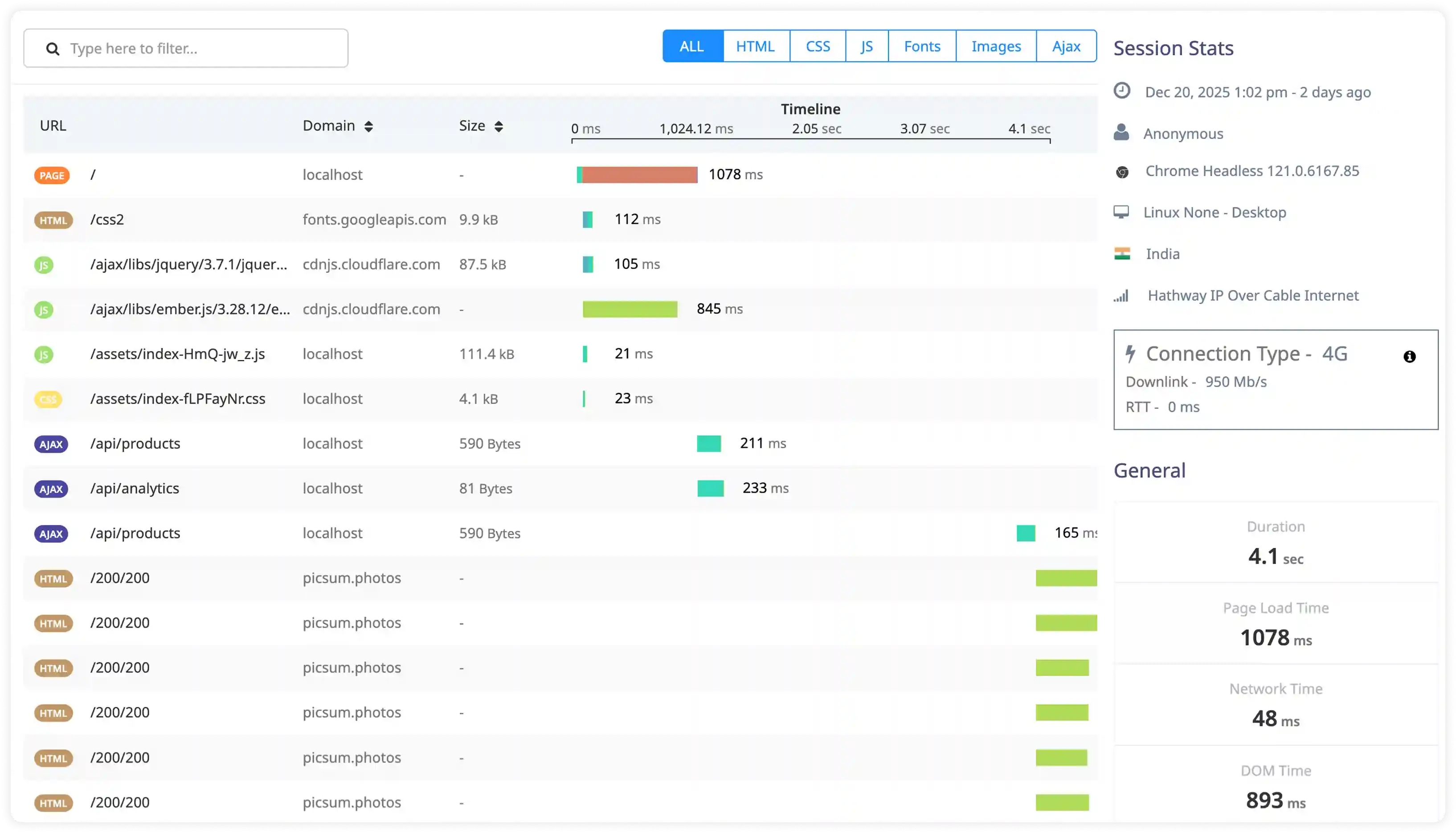
Replication and Sharding Diagnostics
- Capture replication logs, oplog activity, and shard communication events across distributed MongoDB clusters.
- Correlate replication lag and shard balancing behavior with workload spikes and infrastructure conditions.
- Identify recurring synchronization failures and shard inconsistencies affecting cluster reliability.
- Detect operational risks impacting failover readiness and distributed data consistency.
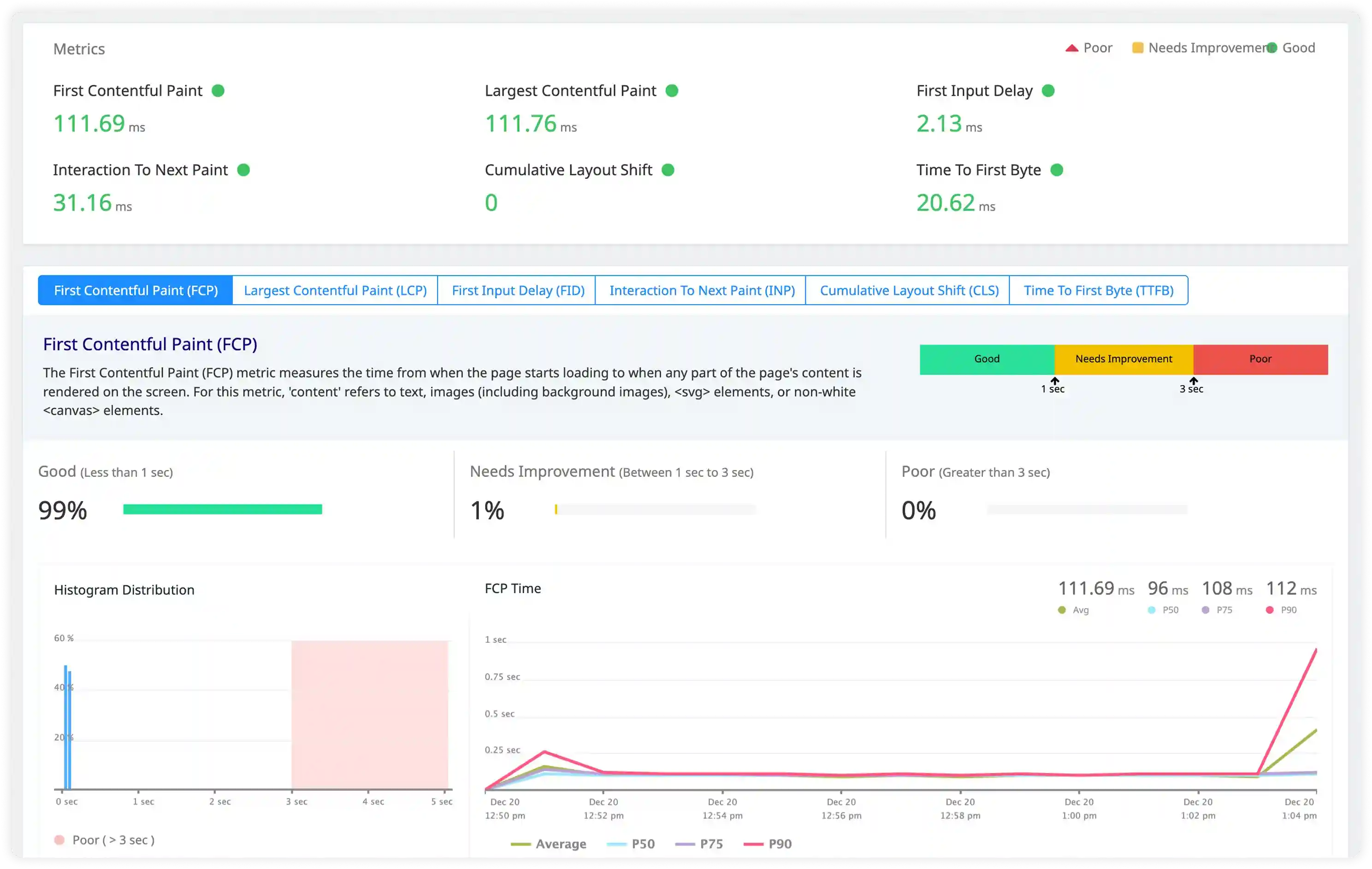
Performance and Index Utilization Signals
- Analyze slow query logs, index usage messages, and execution timing signals affecting MongoDB performance.
- Correlate query behavior with indexing strategy, document size, and workload distribution patterns.
- Identify inefficient queries, missing indexes, and resource contention increasing latency.
- Detect performance degradation through abnormal execution timing and irregular query patterns.
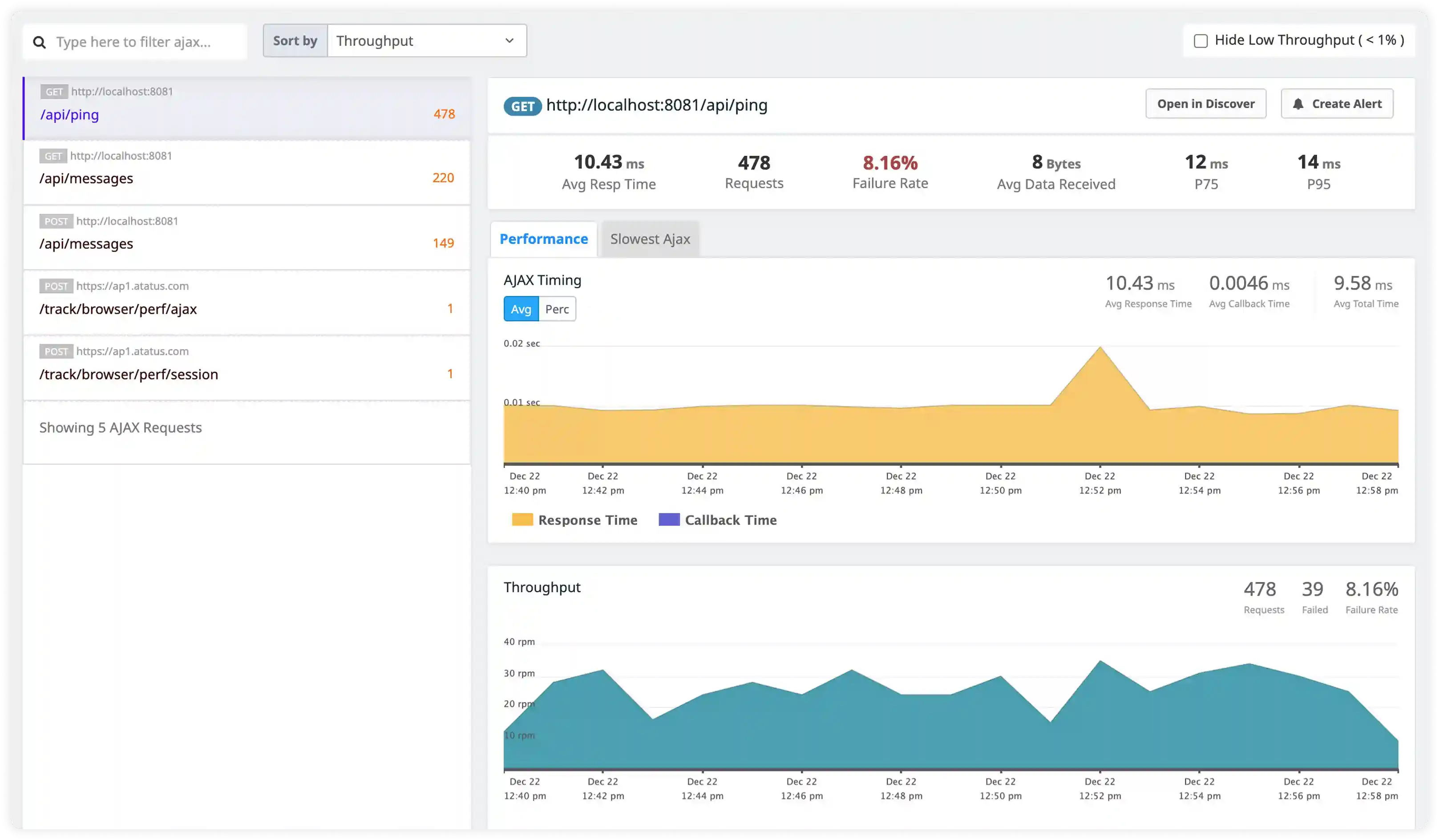
Security and Access Monitoring
- Track authentication attempts, authorization failures, and suspicious database activity captured in MongoDB logs.
- Identify abnormal access patterns, misuse attempts, and unauthorized operations affecting data integrity.
- Correlate database logs with application and infrastructure activity for incident investigation.
- Detect operational and security risks affecting MongoDB deployments.
Why teams choose Atatus for MongoDB logs monitoring
MongoDB-native log insights
Atatus recognizes MongoDB log formats and extracts structured fields like operations, namespaces, timing, and error codes.
Unified cluster visibility
Atatus centralizes logs from standalone nodes, replica sets, and sharded clusters into one searchable timeline.
High-cardinality search
Atatus filters MongoDB logs by database, collection, command type, and error codes for faster troubleshooting.
Real-time alerting
Atatus triggers alerts on slow operations, replication warnings, authentication failures, and critical log events.
Faster root cause analysis
Atatus correlates MongoDB log anomalies with application and infrastructure signals.
Production-scale ingestion
Atatus reliably ingests high-volume MongoDB logs during peak load and maintenance operations.
Unified Observability for Every Engineering Team
Atatus adapts to how engineering teams work across development, operations, and reliability.
Developers
Trace requests, debug errors, and identify performance issues at the code level with clear context.
DevOps
Track deployments, monitor infrastructure impact, and understand how releases affect application stability.
Release Engineer
Measure service health, latency, and error rates to maintain reliability and reduce production risk.